添加聊天记录
在许多问答应用程序中,我们希望允许用户进行来回对话,这意味着应用程序需要一些过去问题和答案的“记忆”,以及一些将它们纳入当前思考的逻辑。
在本指南中,我们重点介绍添加逻辑以合并历史消息。关于聊天记录管理的更多详细信息请参阅此处。
我们将从Lilian Weng (opens in a new tab)在快速入门中发布的“LLM Powered Autonomous Agents”博客文章中构建的问答应用程序开始。我们需要更新现有应用程序的两个方面:
- 提示:更新我们的提示以支持历史消息作为输入。
- 给问题提供背景:添加一个子链,将最新的用户问题放在聊天历史的背景下重新表述。这在最新问题引用了之前消息的某些上下文时是必需的。例如,如果用户问一个跟进问题,比如“你能详细说明第二点吗?”,如果没有之前消息的上下文,这是无法理解的。因此,我们无法有效地使用这样的问题进行检索。
设置
依赖项
本教程中,我们将使用一个OpenAI的聊天模型和嵌入以及一个Chroma向量存储。但是,这里显示的所有内容都适用于任何ChatModel或LLM、Embeddings和VectorStore或Retriever。
我们将使用以下包:
%pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai chromadb bs4我们需要设置环境变量OPENAI_API_KEY,可以直接设置,也可以从.env文件加载,如下所示:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# import dotenv
# dotenv.load_dotenv()LangSmith
您使用LangChain构建的许多应用程序将包含多个步骤和多次LLM调用。随着这些应用程序变得越来越复杂,能够检查链或代理内部发生的情况变得至关重要。最好的方法是使用LangSmith (opens in a new tab)。
请注意,LangSmith不是必需的,但它确实很有帮助。如果您确实想使用LangSmith,请在上面的链接中注册后,确保设置您的环境变量以开始记录跟踪信息:
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()不带聊天记录的链条
以下是我们在Lilian Weng (opens in a new tab)的快速入门中构建的问答应用程序示例:
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter# 加载、分块和索引博客的内容。
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# 使用相关的博客片段进行检索和生成。
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)rag_chain.invoke("What is Task Decomposition?")'Tasks can be broken down into smaller and simpler steps through a technique called task decomposition. This approach helps agents plan and execute tasks more efficiently by dividing them into manageable subgoals. Task decomposition can be achieved using various methods, including prompting techniques, task-specific instructions, or human inputs.'提供问题背景
首先,我们需要定义一个子链,该子链接收历史消息和最新的用户问题,并重新制定问题,如果问题涉及到历史信息中的任何内容。
我们将使用一个提示,该提示在名为“chat_history”的输入中包含一个MessagesPlaceholder变量。这使我们能够使用“chat_history”输入键将一系列消息作为提示的一部分传递给提示,这些消息将插入在包含最新问题的系统消息和人类消息之间。
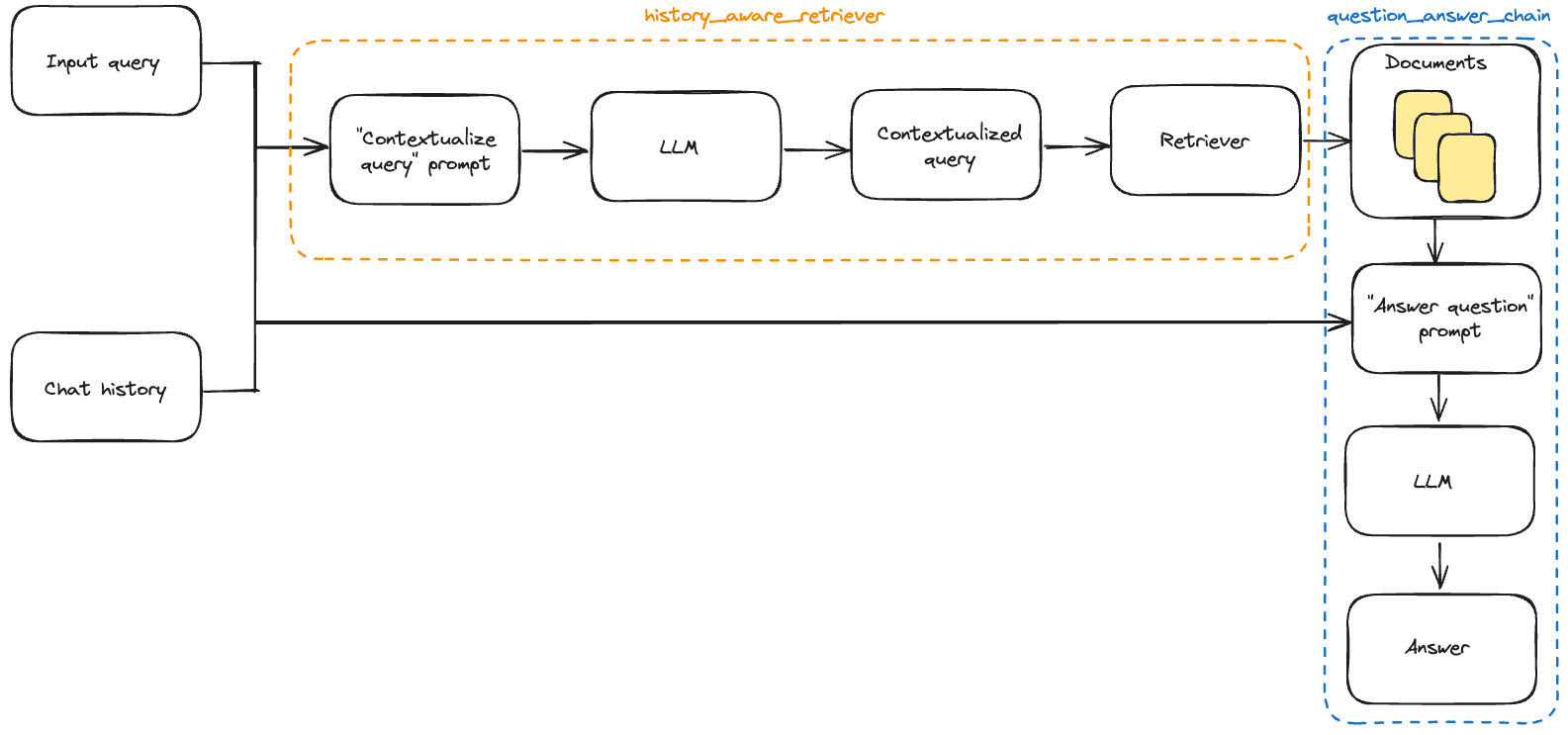
请注意,我们借助辅助函数create_history_aware_retriever (opens in a new tab)来管理这一步骤,该函数处理了chat_history为空的情况,并依次应用prompt | llm | StrOutputParser() | retriever。
create_history_aware_retriever构建了一个链,接受与检索器具有相同输出方案的键(input和chat_history)作为输入,并在检索器之前应用prompt | llm | StrOutputParser()。
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
contextualize_q_system_prompt = """给定一个聊天历史和最新的用户问题,\
该问题可能引用了聊天历史中的一些上下文,\
请组织一个能够在没有聊天历史的情况下理解的独立问题。\
如果需要,重新构思该问题,否则返回原样。"""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)这个链条在我们的检索器之前插入了输入查询的转述,这样检索过程就能包含对话的上下文。
带有聊天记录的链条
现在我们可以构建完整的问答链条了。
在这里,我们使用create_stuff_documents_chain (opens in a new tab)来生成一个question_answer_chain,其输入键为context、chat_history和input--它接受获取的上下文以及对话历史和查询来生成答案。
我们使用create_retrieval_chain (opens in a new tab)构建我们的最终rag_chain。这个链条依次应用history_aware_retriever和question_answer_chain,方便地保留中间输出,如提取的上下文。它的输入键为input和chat_history,并在输出中包括input、chat_history、context和answer。
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
qa_system_prompt = """您是一个用于问答任务的助手。\
请使用以下检索到的上下文片段回答问题。\
如果不知道答案,请说不知道。\
最多使用三个句子,保持答案简洁。
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)from langchain_core.messages import HumanMessage
chat_history = []
question = "What is Task Decomposition?"
ai_msg_1 = rag_chain.invoke({"input": question, "chat_history": chat_history})
chat_history.extend([HumanMessage(content=question), ai_msg_1["answer"]])
second_question = "What are common ways of doing it?"
ai_msg_2 = rag_chain.invoke({"input": second_question, "chat_history": chat_history})
print(ai_msg_2["answer"])任务分解可以通过多种常见方式来完成,包括使用语言模型(LLM)和简单提示,例如“XYZ的步骤”或“实现XYZ的子目标是什么?”;提供针对特定任务量身定制的任务指令;或利用人类输入来指导分解过程。这些方法有助于将复杂的任务分解为更小且更易管理的子任务,以实现高效的执行。:::⚠⚠⚠
请查看LangSmith跟踪 (opens in a new tab)
:::
返回来源
在问答应用程序中,向用户显示生成答案所使用的来源非常重要。LangChain内置的create_retrieval_chain将检索到的源文件通过“context”键传递到输出中:
for document in ai_msg_2["context"]:
print(document)
print()page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.' metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}
page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.' metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}
page_content='Resources:\n1. Internet access for searches and information gathering.\n2. Long Term memory management.\n3. GPT-3.5 powered Agents for delegation of simple tasks.\n4. File output.\n\nPerformance Evaluation:\n1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.\n2. Constructively self-criticize your big-picture behavior constantly.\n3. Reflect on past decisions and strategies to refine your approach.\n4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.' metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}
page_content='Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)\nThe system comprises of 4 stages:\n(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.\nInstruction:' metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}将其联系在一起
这里我们介绍了如何添加应用程序逻辑以将历史输出合并在一起,但是我们仍然需要手动更新聊天历史记录并将其插入到每个输入中。在真实的问答应用程序中,我们希望能够保存聊天历史记录的一种方式,并且自动插入和更新它的一种方式。
为此,我们可以使用:
- BaseChatMessageHistory: 存储聊天历史记录。
- RunnableWithMessageHistory: 一个包装了LCEL链和
BaseChatMessageHistory的包装器,用于将聊天历史记录注入到输入中并在每次调用后更新它。
有关如何将这些类一起使用以创建有状态的对话链的详细演示,请访问如何添加消息历史记录(内存) LCEL页面。
下面,我们在一个单一的代码单元中实现了第二个选项的简单示例,其中聊天历史记录存储在一个简单的字典中。
为了方便起见,我们将所有必要步骤绑定在一个单独的代码单元中:
import bs4
from langchain import hub
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
### 构建检索器 ###
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
### 上下文化问题 ###
contextualize_q_system_prompt = """针对聊天历史记录和最新用户问题(可能引用聊天历史记录中的上下文),构造一个独立的问题,可以理解而不需要聊天历史记录。如果不知道答案,只需说不知道。如下所示简要回答,最多三句话。\
{context}"""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
### 回答问题 ###
qa_system_prompt = """您是一个用于问答任务的助手。使用以下检索到的上下文来回答问题。如果不知道答案,只需说不知道。最多使用三句话,并保持回答简洁。\
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
### 有状态地管理聊天历史记录 ###
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)conversational_rag_chain.invoke(
{"input": "什么是任务分解?"},
config={
"configurable": {"session_id": "abc123"}
}, # 在`store`中构建了一个键为"abc123"的键。
)["answer"]'任务分解是一种将复杂任务拆分为较小且更简单步骤的技术。这种方法通过将任务分解为更可管理的子任务,帮助代理或模型处理困难任务。可以通过Chain of Thought(CoT)或Tree of Thoughts等方法,引导模型逐步思考或在每个步骤上探索多个推理可能性来实现。'
conversational_rag_chain.invoke(
{"input": "常见的做法有哪些?"},
config={"configurable": {"session_id": "abc123"}},
)["answer"]'任务分解可以通过多种常见方法实现,例如使用语言模型(LLM)进行简单提示,使用特定于任务的说明或借助人类输入。例如,可以使用提示“XYZ的步骤”指导LLM拆解任务,或者为任务分解给出特定说明,例如“编写故事大纲”。此外,还可以利用人类输入将任务分解为更小、更可管理的步骤。'