代码理解
使用案例
源代码分析是LLM应用中最受欢迎的之一(例如,GitHub Copilot (opens in a new tab),Code Interpreter (opens in a new tab),Codium (opens in a new tab)和Codeium (opens in a new tab))用于以下用例:
- 对代码库进行问题和答案的查询以了解其工作原理
- 使用LLM提供重构或改进的建议
- 使用LLM编写代码文档
概述
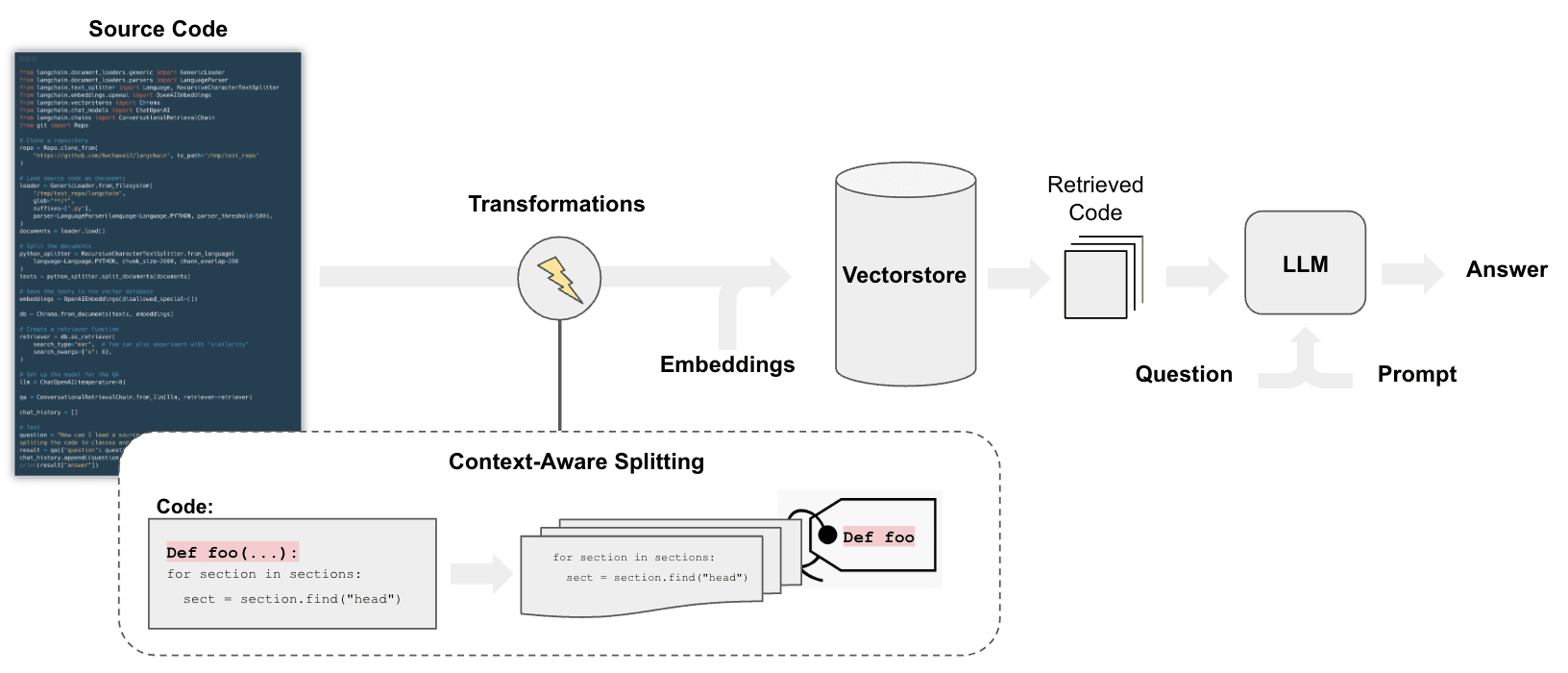
用于对代码进行问题和答案查询的流程与我们用于文档问答的步骤相似(参见/use_cases/question_answering),但也有一些区别:
具体而言,我们可以采用切分策略,执行以下几个操作:
- 将代码中的每个顶级函数和类加载为单独的文档。
- 将剩余代码放入单独的文档中。
- 保留每个切分来自的元数据
快速开始
%pip install --upgrade --quiet langchain-openai tiktoken chromadb langchain git
# 设置环境变量 OPENAI_API_KEY 或从 .env 文件加载
# import dotenv
# dotenv.load_dotenv()我们将按照这个笔记本的结构 (opens in a new tab)并使用上下文感知的代码切分。
加载
我们将使用langchain_community.document_loaders.TextLoader上传所有Python项目文件。
以下脚本遍历LangChain存储库中的文件并加载每个.py文件(也称为文档):
from git import Repo
from langchain_community.document_loaders.generic import GenericLoader
from langchain_community.document_loaders.parsers import LanguageParser
from langchain_text_splitters import Language# Clone
repo_path = "/Users/jacoblee/Desktop/test_repo"
repo = Repo.clone_from("https://github.com/langchain-ai/langchain", to_path=repo_path)我们使用LanguageParser加载py代码,它将执行以下操作:
- 保持顶级函数和类在一起(加载到单个文档中)
- 将剩余代码放入单独的文档中
- 保留每个切分来自的元数据
# Load
loader = GenericLoader.from_filesystem(
repo_path + "/libs/core/langchain_core",
glob="**/*",
suffixes=[".py"],
exclude=["**/non-utf8-encoding.py"],
parser=LanguageParser(language=Language.PYTHON, parser_threshold=500),
)
documents = loader.load()
len(documents)295切分
将Document切分为嵌入和向量存储所需的块。
我们可以使用RecursiveCharacterTextSplitter并指定language。
from langchain_text_splitters import RecursiveCharacterTextSplitter
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=2000, chunk_overlap=200
)
texts = python_splitter.split_documents(documents)
len(texts)898检索QA
我们需要以使我们能够根据其内容进行语义搜索的方式存储文档。
最常见的方法是嵌入每个文档的内容,然后将嵌入和文档存储在向量存储中。
在设置向量存储检索器时:
- 我们测试最大边际相关性以进行检索
- 并返回8个文档
深入了解
- 浏览此处的40多个向量存储集成here (opens in a new tab)。
- 查看有关向量存储的更详细文档here。
- 浏览此处的30多个文本嵌入集成here (opens in a new tab)。
- 查看有关嵌入模型的更详细文档here。
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
db = Chroma.from_documents(texts, OpenAIEmbeddings(disallowed_special=()))
retriever = db.as_retriever(
search_type="mmr", # 也可以尝试 "similarity"
search_kwargs={"k": 8},
)聊天
测试聊天,就像我们为chatbots做的那样。
深入了解
- 浏览此处的55多个LLM和聊天模型集成here (opens in a new tab)。
- 查看有关LLM和聊天模型的更详细文档here。
- 使用本地LLMs:PrivateGPT (opens in a new tab)和GPT4All (opens in a new tab)的受欢迎程度强调了在本地运行LLMs的重要性。
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4")
# 首先,我们需要一个提示,可以将其传递到LLM中以生成此搜索查询
prompt = ChatPromptTemplate.from_messages(
[
("placeholder", "{chat_history}"),
("user", "{input}"),
(
"user",
"根据上面的对话,生成一个搜索查询,以获取与对话相关的信息",
),
]
)
retriever_chain = create_history_aware_retriever(llm, retriever, prompt)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"根据以下上下文回答用户的问题:\n\n{context}",
),
("placeholder", "{chat_history}"),
("user", "{input}"),
]
)
document_chain = create_stuff_documents_chain(llm, prompt)
qa = create_retrieval_chain(retriever_chain, document_chain)question = "什么是RunnableBinding?"
result = qa.invoke({"input": question})
result["answer"]'RunnableBinding是LangChain库中用于将参数绑定到Runnable的类之一。当链中的可运行对象需要一个不在前一个可运行对象的输出中或用户输入中的参数时,这就很有用。它返回一个带有绑定参数和配置的新Runnable。RunnableBinding类中的bind方法用于执行此操作。'questions = [
"有哪些类是从Runnable类派生的?",
"在与Runnable类相关的类层次结构的代码中,你提议的一种改进是什么?",
]
for question in questions:
result = qa.invoke({"input": question})
print(f"-> **问题**: {question} \n")
print(f"**回答**: {result['answer']} \n")-> **问题**: 有哪些类是从Runnable类派生的?
**回答**: 按照上下文中提到的,从`Runnable`类派生的类有:`RunnableLambda`,`RunnableLearnable`,`RunnableSerializable`,`RunnableWithFallbacks`。
-> **问题**: 在与Runnable类相关的类层次结构的代码中,你提议的一种改进是什么?
**回答**: 一个潜在的改进可能是为不同类型的Runnable类引入抽象基类(ABC)或接口。目前,似乎有很多不同的Runnable类型,比如RunnableLambda,RunnableParallel等,每个类型都有自己的方法和属性。通过为所有这些类定义一个公共接口或ABC,我们可以确保一致性并更好地组织代码库。这也将使将来添加新类型的可运行类更容易,因为它们只需要实现接口或ABC中定义的方法即可。
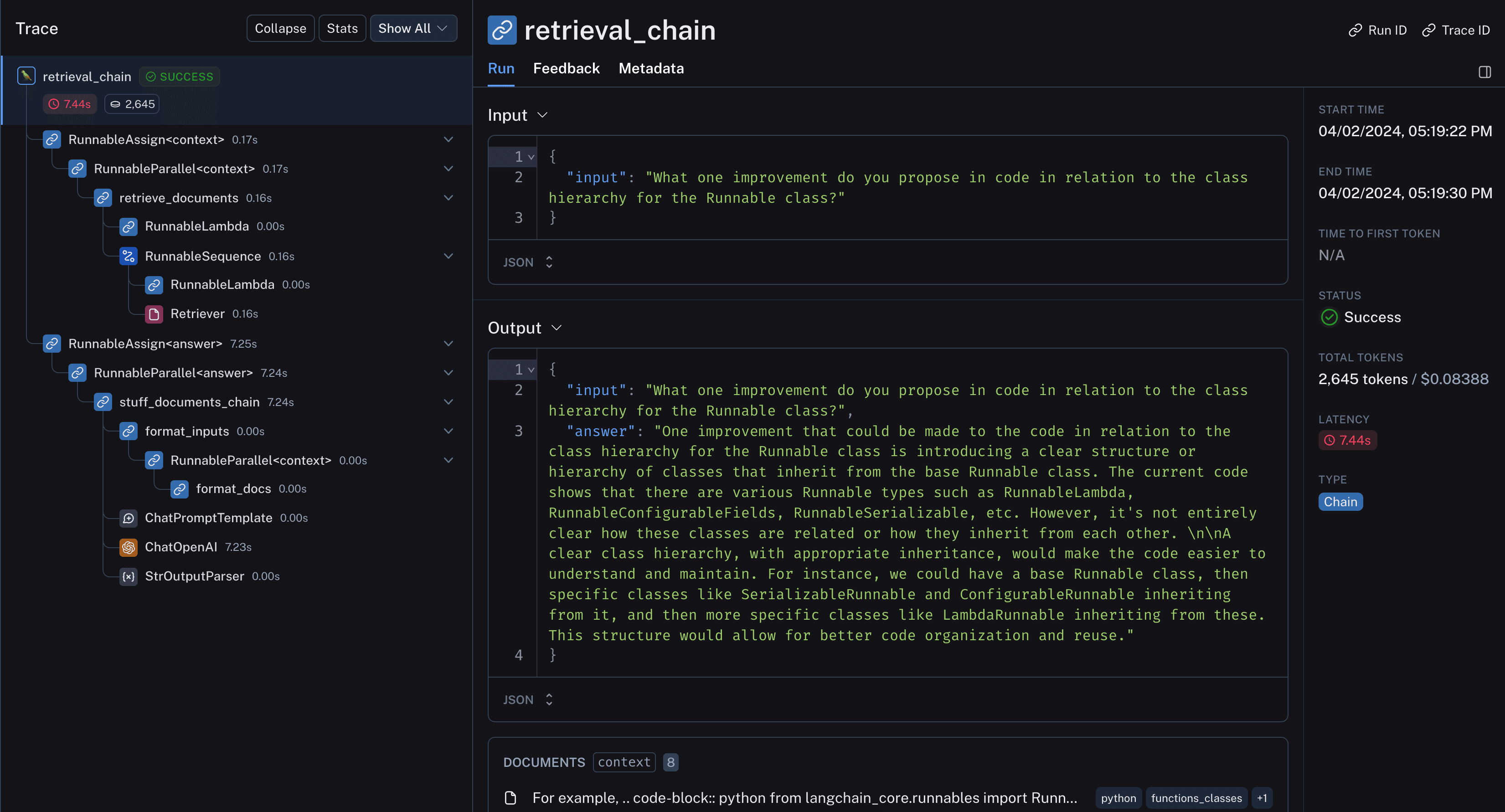
然后,我们可以查看LangSmith跟踪 (opens in a new tab)以了解底层发生了什么:
- 特别是代码结构良好,并在检索输出中保持在一起
- 将检索到的代码和聊天记录传递给LLM进行答案精炼
开源LLM
我们将使用LangChain的Ollama集成 (opens in a new tab)来查询本地的开源模型。
在这里查看最新的可用模型here (opens in a new tab)。
%pip install --upgrade --quiet langchain-communityfrom langchain_community.chat_models.ollama import ChatOllama
llm = ChatOllama(model="codellama")让我们使用一个通用的编码问题来运行它,以测试它的知识:
response_message = llm.invoke(
"In bash, how do I list all the text files in the current directory that have been modified in the last month?"
)
print(response_message.content)
print(response_message.response_metadata)你可以使用`find`命令和`-mtime`选项来查找在当前目录中修改时间在最近一个月内的所有文本文件。下面是一个示例命令:
```bash
find . -type f -name "*.txt" -mtime -30这将列出在当前目录(.)中修改时间在最近30天内的所有文本文件。-type f选项确保只匹配普通文件,而不是目录或其他类型的文件。-name "*.txt"选项将搜索范围限制在扩展名为.txt的文件上。最后,-mtime -30选项指定我们要查找修改时间在最近30天内的文件。
您还可以使用find命令和-mmin选项来查找在当前目录中在最近一个月内已修改的所有文本文件。下面是一个示例命令:
find . -type f -name "*.txt" -mmin -4320这将列出在当前目录(.)中修改时间在最近30天内的所有文本文件。-type f选项确保只匹配普通文件,而不是目录或其他类型的文件。-name "*.txt"选项将搜索范围限制在扩展名为.txt的文件上。最后,-mmin -4320选项指定我们要查找修改时间在最近4320分钟内的文件(相当于一个月的时间)。
您还可以使用ls命令和-l选项,并将其管道到grep命令以过滤出文本文件。下面是一个示例命令:
ls -l | grep "*.txt"这将列出在当前目录(.)中修改时间在最近30天内的所有文本文件。ls命令的-l选项以长格式列出文件,包括修改时间,grep命令过滤掉与指定模式不匹配的文件。
请注意,这些命令区分大小写,所以如果您有不同扩展名的文件(例如.TXT),它们将不会被这些命令匹配到。
{'model': 'codellama', 'created_at': '2024-04-03T00:41:44.014203Z', 'message': {'role': 'assistant', 'content': ''}, 'done': True, 'total_duration': 27078466916, 'load_duration': 12947208, 'prompt_eval_count': 44, 'prompt_eval_duration': 11497468000, 'eval_count': 510, 'eval_duration': 15548191000}
看起来很合理!现在让我们使用之前加载的vectorstore进行设置。
我们省略对话方面,以使事情对于低功耗本地模型更易于管理:
```python
# from langchain.chains.question_answering import load_qa_chain
# # Prompt
# template = """Use the following pieces of context to answer the question at the end.
# If you don't know the answer, just say that you don't know, don't try to make up an answer.
# Use three sentences maximum and keep the answer as concise as possible.
# {context}
# Question: {question}
# Helpful Answer:"""
# QA_CHAIN_PROMPT = PromptTemplate(
# input_variables=["context", "question"],
# template=template,
# )
system_template = """
Answer the user's questions based on the below context.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible:
{context}
"""
# First we need a prompt that we can pass into an LLM to generate this search query
prompt = ChatPromptTemplate.from_messages(
[
("system", system_template),
("user", "{input}"),
]
)
document_chain = create_stuff_documents_chain(llm, prompt)
qa_chain = create_retrieval_chain(retriever, document_chain)# Run, only returning the value under the answer key for readability
qa_chain.pick("answer").invoke({"input": "What is a RunnableBinding?"})结果不完美,但它已经注意到了它允许开发人员设置配置选项!
这里是LangSmith跟踪 (opens in a new tab),显示用作上下文的检索到的文档。