所有可用代理分类
这将所有可用代理分类在几个维度上。
预期的模型类型
这个代理是为聊天模型(接收消息,输出消息)还是LLMs(接收字符串,输出字符串)而设计的。这主要影响的是使用的提示策略。您可以使用不同类型模型的代理,但可能不会产生相同质量的结果。
支持聊天历史记录
这些代理类型是否支持聊天历史记录。如果支持,那意味着它可以用作聊天机器人。如果不支持,则意味着更适用于单个任务。支持聊天历史通常需要更好的模型,因此早期针对较差模型的代理类型可能不支持。
支持多输入工具
这些代理类型是否支持具有多个输入的工具。如果工具只需要一个输入,LLM通常更容易知道如何调用它。因此,一些早期针对较差模型的代理类型可能不支持这些工具。
支持并行功能调用
LLM同时调用多个工具可以极大地加快代理是否有任务需要这样做的速度。但是,对于LLM来说这样做要困难得多,因此一些代理类型不支持这一点。
模型所需的参数
是否需要该代理要求模型支持任何额外的参数。一些代理类型利用诸如OpenAI函数调用之类的功能,这些功能需要其他模型参数。如果不需要任何参数,那意味着所有操作都是通过提示完成的。
何时使用
我们对您何时应该考虑使用此代理类型的评论。
| 代理类型 | 预期的模型类型 | 支持聊天历史记录 | 支持多输入工具 | 支持并行功能调用 | 需要的模型参数 | 何时使用 | API |
|---|---|---|---|---|---|---|---|
| 工具调用 | 聊天 | ✅ | ✅ | ✅ | tools | 如果您正在使用一个工具调用模型 | Ref (opens in a new tab) |
| OpenAI工具 | 聊天 | ✅ | ✅ | ✅ | tools | [Legacy]如果您使用最近的OpenAI模型(从1106开始)。建议使用通用工具调用代理代替。 | Ref (opens in a new tab) |
| OpenAI函数 | 聊天 | ✅ | ✅ | functions | [Legacy]如果您使用OpenAI模型,或经过微调以进行函数调用并公开与OpenAI相同的functions参数的开源模型。建议使用通用工具调用代理代替。 | Ref (opens in a new tab) | |
| XML | LLM | ✅ | 如果您正在使用Anthropic模型,或其他擅长XML的模型 | Ref (opens in a new tab) | |||
| 结构化聊天 | 聊天 | ✅ | ✅ | 如果您需要支持具有多个输入的工具 | Ref (opens in a new tab) | ||
| JSON聊天 | 聊天 | ✅ | 如果您正在使用擅长处理JSON的模型 | Ref (opens in a new tab) | |||
| ReAct | LLM | ✅ | 如果您正在使用一个简单的模型 | Ref (opens in a new tab) | |||
| 自问带搜索 | LLM | 如果您正在使用一个简单的模型,并且只有一个搜索工具 | Ref (opens in a new tab) |
The core idea of agents is to use a language model to choose a sequence of actions to take. In chains, a sequence of actions is hardcoded (in code). In agents, a language model is used as a reasoning engine to determine which actions to take and in which order.
快速入门
要快速入门代理的工作,请查看此入门指南。这包括像初始化代理、创建工具和添加记忆等基础知识。
概念
在构建代理时需要了解的几个关键概念:代理、代理执行器、工具、工具包。 要深入了解,请查看这份概念指南。
代理类型
有许多不同类型的代理可供使用。要了解不同类型及何时使用它们,请查看此部分。
工具
代理只有工具齐全才能发挥作用。要全面了解工具,请参阅此部分。
操作指南
代理有许多相关功能!查看包括:
- 构建自定义代理
- 流式处理(包括中间步骤和标记的流式处理)
- 构建返回结构化输出的代理
- 使用AgentExecutor的多功能性,包括:将其用作迭代器、处理解析错误、返回中间步骤、限制最大迭代次数和代理的超时
回调函数
:::🗒️ 请前往Integrations查看与第三方工具集成的内置回调函数集成文档。 :::
LangChain提供了一个回调函数系统,允许您钩入LLM应用程序的各个阶段。这对于日志记录、监控、流式处理和其他任务非常有用。
您可以通过在整个API中可用的callbacks参数来订阅这些事件。该参数是处理程序对象的列表,这些对象应实现下面更详细描述的一个或多个方法。
回调处理程序
CallbackHandlers是实现CallbackHandler接口的对象,该接口为每个可以订阅的事件定义了一个方法。当事件触发时,CallbackManager将在每个处理程序上调用相应的方法。
class BaseCallbackHandler:
"""可用于处理来自langchain的回调的基本回调处理程序。"""
def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> Any:
"""LLM开始运行时运行。"""
def on_chat_model_start(
self, serialized: Dict[str, Any], messages: List[List[BaseMessage]], **kwargs: Any
) -> Any:
"""Chat Model开始运行时运行。"""
def on_llm_new_token(self, token: str, **kwargs: Any) -> Any:
"""在新LLM令牌上运行。仅在启用流式处理时可用。"""
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> Any:
"""LLM结束运行时运行。"""
def on_llm_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> Any:
"""处理LLM错误时运行。"""
def on_chain_start(
self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any
) -> Any:
"""链开始运行时运行。"""
def on_chain_end(self, outputs: Dict[str, Any], **kwargs: Any) -> Any:
"""链结束运行时运行。"""
def on_chain_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> Any:
"""处理链错误时运行。"""
def on_tool_start(
self, serialized: Dict[str, Any], input_str: str, **kwargs: Any
) -> Any:
"""工具开始运行时运行。"""
def on_tool_end(self, output: Any, **kwargs: Any) -> Any:
"""工具结束运行时运行。"""
def on_tool_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> Any:
"""处理工具错误时运行。"""
def on_text(self, text: str, **kwargs: Any) -> Any:
"""在任意文本上运行。"""
def on_agent_action(self, action: AgentAction, **kwargs: Any) -> Any:
"""处理代理动作时运行。"""
def on_agent_finish(self, finish: AgentFinish, **kwargs: Any) -> Any:
"""在代理结束时运行。"""入门
LangChain提供了一些内置处理程序,可帮助您入门。这些在langchain_core/callbacks模块中可用。最基本的处理程序是StdOutCallbackHandler,它只是将所有事件记录到stdout。
注意:当对象上的verbose标志设置为true时,StdOutCallbackHandler将被调用,即使没有明确传递进来。
from langchain_core.callbacks import StdOutCallbackHandler
from langchain.chains import LLMChain
from langchain_openai import OpenAI
from langchain_core.prompts import PromptTemplate
handler = StdOutCallbackHandler()
llm = OpenAI()
prompt = PromptTemplate.from_template("1 + {number} = ")
# 构造回调:首先,在初始化链时明确设置StdOutCallbackHandler
chain = LLMChain(llm=llm, prompt=prompt, callbacks=[handler])
chain.invoke({"number":2})
# 使用verbose标志:然后,让我们使用`verbose`标志来达到相同的结果
chain = LLMChain(llm=llm, prompt=prompt, verbose=True)
chain.invoke({"number":2})
# 请求回调:最后,让我们使用请求`callbacks`来达到相同的结果
chain = LLMChain(llm=llm, prompt=prompt)
chain.invoke({"number":2}, {"callbacks":[handler]})
> 进入新的LLMChain链...
格式化后的提示:
1 + 2 =
> 完成链。
> 进入新的LLMChain链...
格式化后的提示:
1 + 2 =
> 完成链。
> 进入新的LLMChain链...
格式化后的提示:
1 + 2 =
> 完成链。在哪里传递回调
callbacks在API的大多数对象(链、模型、工具、代理等)中都可以找到,可以存在两个不同的位置:
- 构造函数回调:在构造函数中定义,例如
LLMChain(callbacks=[handler], tags=['a-tag'])。在这种情况下,回调将用于该对象上的所有调用,并且将仅限于该对象,例如,如果您将处理程序传递给LLMChain构造函数,则不会被用于附加到该链的模型。 - 请求回调:定义在用于发出请求的“invoke”方法中。在这种情况下,回调仅用于该特定请求,以及其中包含的所有子请求(例如,调用LLMChain会触发对Model的调用,后者使用传递给
invoke()方法的同一个处理程序)。在invoke()方法中,回调通过config参数传递。 使用“invoke”方法的示例(注意:相同的方法可以用于batch、ainvoke和abatch方法。):
handler = StdOutCallbackHandler()
llm = OpenAI()
prompt = PromptTemplate.from_template("1 + {number} = ")
config = {
'callbacks' : [handler]
}
chain = prompt | chain
chain.invoke({"number":2}, config=config)注意:chain = prompt | chain等同于chain = LLMChain(llm=llm, prompt=prompt)(查看更多详情,请参阅LangChain表达式语言(LCEL)文档)
verbose参数在API的大多数对象(链、模型、工具、代理等)中作为构造函数参数可用,例如,LLMChain(verbose=True),它等同于将ConsoleCallbackHandler传递给该对象及所有子对象的callbacks参数。这对于调试很有用,因为它会将所有事件记录到控制台。
您何时想使用这些方法?
- 构造函数回调最适用于例如日志记录、监控等与单个请求无关的用例,而是与整个链相关的用例。例如,如果您想要记录所有发送到
LLMChain的请求,您将在构造函数中传递处理程序。 - 请求回调对于流式处理等用例非常有用,您希望将单个请求的输出流到特定的websocket连接或其他类似用例。例如,如果您想将单个请求的输出流式传输到websocket,您将在
invoke()方法中传递处理程序
文档加载器
:::🗒️ 请转到Integrations查看关于与第三方工具集成的内置文档加载器集成文档。 :::
使用文档加载器从源加载数据为Document。Document是一段文本和相关的元数据。例如,有用于加载简单的.txt文件的文档加载器,用于加载任何网页的文本内容,甚至用于加载YouTube视频的转录。
文档加载器提供了一个"load"方法,用于从配置的源加载数据为文档。它们还可以选择实现一个"lazy load",以便将数据懒加载到内存中。
入门指南
最简单的加载器将文件读取为文本,并将其全部放入一个文档中。
from langchain_community.document_loaders import TextLoader
loader = TextLoader("./index.md")
loader.load()[
Document(page_content='---\nsidebar_position: 0\n---\n# Document loaders\n\nUse document loaders to load data from a source as `Document`\'s. A `Document` is a piece of text\nand associated metadata. For example, there are document loaders for loading a simple `.txt` file, for loading the text\ncontents of any web page, or even for loading a transcript of a YouTube video.\n\nEvery document loader exposes two methods:\n1. "Load": load documents from the configured source\n2. "Load and split": load documents from the configured source and split them using the passed in text splitter\n\nThey optionally implement:\n\n3. "Lazy load": load documents into memory lazily\n', metadata={'source': '../modules/data_connection/document_loaders/index.md'})
]文本分割器
一旦您加载了文档,通常希望转换它们以更好地适应您的应用程序。最简单的例子是您可能希望将一份长文档拆分为较小的块,以适应您模型的上下文窗口。LangChain 提供了许多内置的文档转换器,使拆分、合并、过滤和其他操作文档变得轻松。
当您想处理长篇文本时,有必要将该文本拆分成块。 这听起来很简单,但这里存在很多潜在的复杂性。理想情况下,您希望将语义相关的文本片段放在一起。"语义相关" 的含义可能取决于文本的类型。 本笔记展示了几种实现这一目标的方法。
总体而言,文本分割器的工作方式如下:
- 将文本拆分成小的、语义上有意义的块(通常是句子)。
- 将这些小块合并成较大的块,直到达到某个大小(通过某个函数进行度量)。
- 一旦达到该大小,将该块作为自己的文本片段,然后开始创建一个具有某种重叠的新文本块(以保持块之间的上下文)。
这意味着您可以沿着两个不同的轴自定义文本分割器:
- 文本如何拆分
- 文本块大小如何度量
文本分割器的类型
LangChain 提供了许多不同类型的文本分割器。它们都位于 langchain-text-splitters 包中。下面是一个列表,其中列出了它们所有的名称以及一些特点:
名称:文本分割器的名称
拆分依据:该文本分割器如何拆分文本
是否添加元数据:该文本分割器是否添加关于每个文本块来自何处的元数据
描述:该拆分器的简介,包括何时使用的推荐说明
| 名称 | 拆分依据 | 是否添加元数据 | 描述 |
|---|---|---|---|
| 递归 | 用户定义的字符列表 | 递归地拆分文本。递归拆分文本的目的是尽量将相关的文本片段放在一起。这是开始拆分文本的推荐方式。 | |
| HTML | HTML 特定字符 | ✅ | 基于 HTML 特定字符拆分文本。值得注意的是,这会根据 HTML 参考的相关信息添加到每个文本块的来源中 |
| Markdown | Markdown 特定字符 | ✅ | 基于 Markdown 特定字符拆分文本。值得注意的是,这会根据 Markdown 参考的相关信息添加到每个文本块的来源中 |
| 代码 | 代码(Python、JS)特定字符 | 基于编程语言特定字符拆分文本。共提供了 15 种不同的语言可供选择。 | |
| Token | Token | 基于 Token 拆分文本。有几种不同的计算 Token 的方法。 | |
| 字符 | 用户定义的字符 | 基于用户定义的字符拆分文本。这是较为简单的方法之一。 | |
| [实验] 语义块拆分器 | 句子 | 首先根据句子进行拆分。然后,如果相邻的句子在语义上足够相似,就将它们合并在一起。取自 Greg Kamradt (opens in a new tab) | |
| AI21 语义文本分割器 | 语义 | ✅ | 识别构成连贯文本片段的不同主题,并在这些主题之间进行拆分。 |
评估文本分割器
您可以使用 Greg Kamradt 创建的 Chunkviz 实用工具 (opens in a new tab) 来评估文本分割器。
Chunkviz 是一个非常好的工具,用于可视化文本分割器的工作方式。它将显示您的文本是如何被拆分的,并帮助调整拆分参数。
其他文档转换
文本拆分只是对文档进行转换的示例之一,在将其传递给 LLM 之前,您可能还想对文档进行其他转换。请前往 Integrations 查看有关与第三方工具集成的内置文档转换器的文档。# 检索
许多LLM应用程序需要用户特定的数据,这些数据不是模型的训练集的一部分。 通过检索增强生成(RAG)来完成这个目标。 在这个过程中,外部数据被"检索",然后在执行"生成"步骤时传递给LLM。
LangChain提供了从简单到复杂的RAG应用程序的所有构建模块。 文档的这一部分涵盖了与检索步骤相关的所有内容,例如数据的获取。 虽然这听起来很简单,但实际上可能有微妙的复杂性。 这包括几个关键模块。
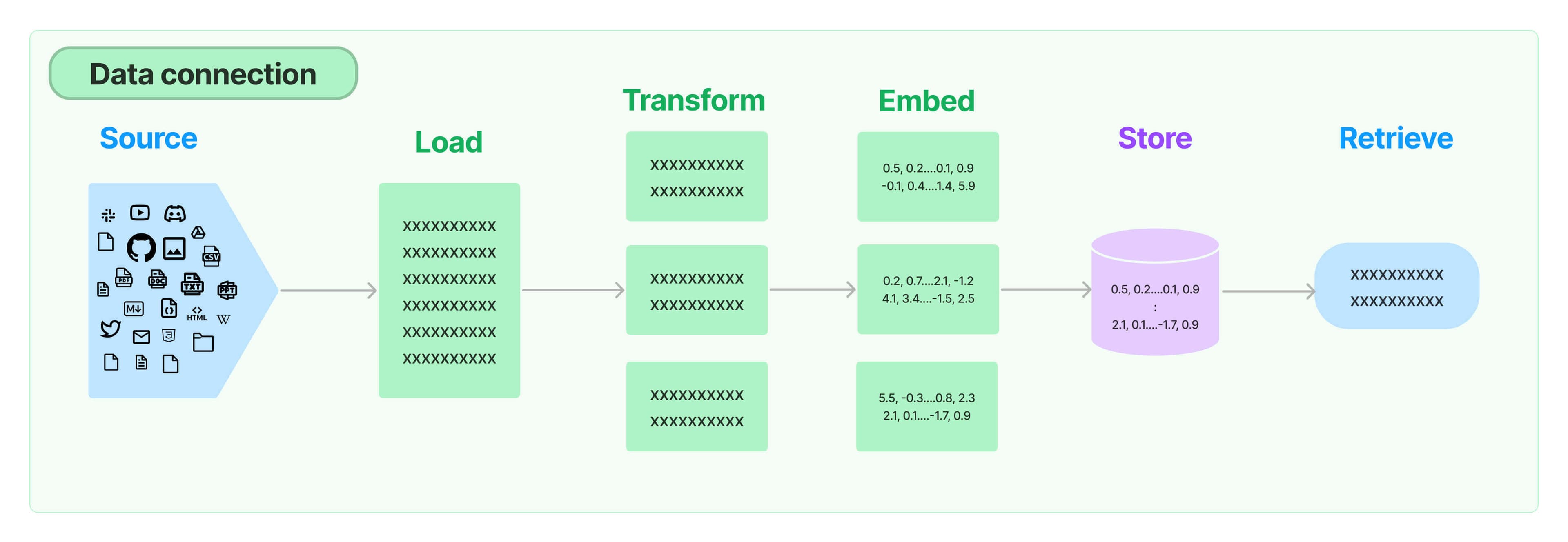
文档加载器
文档加载器从许多不同的来源加载文档。 LangChain提供了100多个不同的文档加载器,以及与空间中其他主要提供商的集成,如AirByte和Unstructured。 LangChain提供与所有类型的位置(私有S3存储桶、公共网站)上的所有类型的文档(HTML、PDF、代码)加载的集成。
文本分割
检索的一个关键部分是只获取文档中相关的部分。 这涉及几个转换步骤,以准备文档进行检索。 其中一个主要的步骤是将大型文档分割成较小的块。 LangChain提供了几个用于执行此操作的转换算法,以及针对特定文档类型(代码、markdown等)进行优化的逻辑。
文本嵌入模型
检索的另一个关键部分是为文档创建嵌入。 嵌入捕捉文本的语义含义,使您能够快速高效地找到其他相似的文本片段。 LangChain提供与25多个不同的嵌入提供商和方法的集成,从开源到专有API, 让您可以选择最适合您需求的那个。 LangChain提供了一个标准的接口,使您可以轻松地在不同模型之间进行切换。
向量存储
随着嵌入的兴起,出现了对支持这些嵌入的数据库进行高效存储和搜索的需求。 LangChain提供与50多个不同的向量存储的集成,从开源的本地存储到云托管的专有存储, 让您可以选择最适合您需求的那个。 LangChain公开了一个标准的接口,使您可以轻松地在不同的向量存储之间切换。
检索器
一旦数据在数据库中,您仍然需要检索它。 LangChain支持许多不同的检索算法,这是我们增加的最有价值的部分之一。 LangChain支持易于入门的基本方法,即简单的语义搜索。 然而,我们还在此基础上添加了一系列算法来提高性能。 这些包括:
- 父文档检索器:允许您为每个父文档创建多个嵌入,从而允许您查找较小的块但返回较大的上下文。
- 自查询检索器:用户的问题通常包含一个不仅仅是语义的引用,而是表达一些逻辑的东西,最好将其表示为元数据过滤器。自查询器允许您从查询中解析出语义部分和其他元数据过滤器。
- 集合检索器:有时您可能希望从多个不同的源检索文档,或者使用多种不同的算法。集合检索器允许您轻松实现这一点。
- 等等!
索引
LangChain的索引API将您的数据从任何来源同步到向量存储中, 帮助您:
- 避免将重复内容写入向量存储
- 避免重新编写未更改的内容
- 避免在未更改的内容上重新计算嵌入
这些都应该节省您的时间和金钱,同时提高向量搜索的结果。
检索器
检索器是一个接口,在给定一个非结构化查询的情况下返回文档。它比向量存储更通用。 检索器不需要能够存储文档,只需要返回(或检索)它们。向量存储可以用作检索器的基础,但也有其他类型的检索器。
检索器接受一个字符串查询作为输入,并返回一个 Document 列表作为输出。
高级检索类型
LangChain 提供了几种高级检索类型。完整列表如下,以及以下信息:
名称:检索算法的名称。
索引类型:此算法依赖的索引类型(如果有)。
使用 LLM:此检索方法是否使用 LLM。
何时使用:我们对何时应考虑使用此检索方法的评论。
描述:此检索算法在执行什么。
| 名称 | 索引类型 | 使用 LLM | 何时使用 | 描述 |
|---|---|---|---|---|
| Vectorstore | Vectorstore | 否 | 如果您刚开始并且正在寻找一些快速简单的内容。 | 这是最简单的方法,也是最容易入门的方法。它涉及为每个文本创建嵌入。 |
| ParentDocument | Vectorstore + 文档存储库 | 否 | 如果您的页面包含许多较小的不同信息块,最好将它们单独索引,但最好一起检索。 | 这涉及为每个文档索引多个块。然后找到在嵌入空间中最相似的块,但检索整个父文档并返回(而不是单独的块)。 |
| Multi Vector | Vectorstore + 文档存储库 | 有时在索引期间 | 如果您能从文档中提取信息,认为这些信息比文本本身更相关。 | 这涉及为每个文档创建多个向量。每个向量可以以多种方式创建 - 例如包括文本摘要和假设问题。 |
| Self Query | Vectorstore | 是 | 如果用户提出的问题更适合通过基于元数据而不是与文本的相似性来检索文档来回答。 | 这使用 LLM 将用户输入转换为两个内容:(1)一个要查找的语义上相似的字符串,(2)一个要与之配合的元数据过滤器。这很有用,因为通常问题是关于文档的 METADATA(而不是内容本身)。 |
| Contextual Compression | 任何 | 有时候 | 如果您发现检索的文档包含太多无关信息,并且在转移学习中分散了 LLM 的注意力。 | 这在另一个检索器之上添加后处理步骤,并从检索的文档中提取出最相关的信息。这可以使用嵌入或 LLM 完成。 |
| Time-Weighted Vectorstore | Vectorstore | 否 | 如果您的文档关联有时间戳,并且希望检索最近的文档 | 这根据语义相似性(与正常向量检索一样)和最近性(查看索引文档的时间戳)检索文档 |
| Multi-Query Retriever | 任何 | 是 | 如果用户提出的问题很复杂,需要多个不同信息块来回复 | 这使用 LLM 从原始查询生成多个查询。当原始查询需要关于多个主题的信息块才能得到正确答案时,这很有用。通过生成多个查询,我们可以为每个查询获取文档。 |
| Ensemble | 任何 | 否 | 如果您有多种检索方法,并希望尝试将它们结合起来。 | 这从多个检索器中获取文档,然后将它们组合起来。 |
| Long-Context Reorder | 任何 | 否 | 如果您正在使用长上下文模型,并且注意到它没有关注已检索文档中间的信息。 | 这从底层检索器检索文档,然后重新排序文档,以使最相似的文档靠近开头和结尾。这是有用的,因为已经证明对于更长的上下文模型,有时它们忽略了上下文窗口中间的信息。 |
第三方集成
LangChain 还与许多第三方检索服务集成。要查看完整列表,请查看所有集成的 此列表。
在 LCEL 中使用检索器
由于检索器是 Runnable,我们可以轻松将它们与其他 Runnable 对象组合:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
template = """仅基于以下上下文回答问题:
{context}
问题:{question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
def format_docs(docs):
return "\n\n".join([d.page_content for d in docs])
chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
chain.invoke("总统对技术说了什么?")
自定义检索器
由于检索器接口如此简单,编写自定义检索器相当容易。
from langchain_core.retrievers import BaseRetriever
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.documents import Document
from typing import List
class CustomRetriever(BaseRetriever):
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
return [Document(page_content=query)]
retriever = CustomRetriever()
retriever.get_relevant_documents("bar")
```# 文本嵌入模型
:::🗒️
请前往[Integrations](/docs/integrations/text_embedding/)查看与文本嵌入模型提供商内置集成的文档。
:::
Embeddings类是一个设计用于与文本嵌入模型进行接口的类。有许多嵌入模型提供商(OpenAI,Cohere,Hugging Face等)-该类旨在为所有这些提供商提供一个标准接口。
嵌入模型会创建文本的向量表示。这很有用,因为这意味着我们可以在向量空间中思考文本,并执行诸如语义搜索之类的操作,在其中查找在向量空间中最相似的文本片段。
LangChain中的基本Embeddings类提供了两种方法:用于嵌入文档和用于嵌入查询。前者以多个文本作为输入,而后者以单个文本作为输入。之所以将它们作为两个单独的方法,是因为一些嵌入提供商针对文档(用于搜索)与查询(搜索查询本身)具有不同的嵌入方法。
## 入门
### 设置
import Tabs from '@theme/Tabs';
import TabItem from '@theme/TabItem';
<Tabs>
<TabItem value="openai" label="OpenAI" default>
首先,我们需要安装OpenAI合作伙伴包:
```bash
pip install langchain-openai访问API需要API密钥,您可以通过创建帐户并转到此处 (opens in a new tab)来获取密钥。一旦我们有了密钥,我们希望将其设置为环境变量,方法是运行:
export OPENAI_API_KEY="..."如果您不想设置环境变量,可以在初始化OpenAI LLM类时通过“api_key”命名参数直接传递密钥:
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(api_key="...")否则,您可以不带任何参数进行初始化:
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()首先,我们需要安装Cohere SDK包:
pip install langchain-cohere访问API需要API密钥,您可以通过创建帐户并转到此处 (opens in a new tab)来获取密钥。一旦我们有了密钥,我们希望将其设置为环境变量,方法是运行:
export COHERE_API_KEY="..."如果您不想设置环境变量,可以在初始化Cohere LLM类时通过“cohere_api_key”命名参数直接传递密钥:
from langchain_cohere import CohereEmbeddings
embeddings_model = CohereEmbeddings(cohere_api_key="...")否则,您可以不带任何参数进行初始化:
from langchain_cohere import CohereEmbeddings
embeddings_model = CohereEmbeddings()embed_documents
嵌入文本列表
embeddings = embeddings_model.embed_documents(
[
"嗨!",
"哦,你好!",
"你叫什么名字?",
"我的朋友叫我World",
"你好,世界!"
]
)
len(embeddings), len(embeddings[0])(5, 1536)embed_query
嵌入单个查询
嵌入单个文本片段,以便与其他嵌入文本进行比较。
embedded_query = embeddings_model.embed_query("对话中提到的名字是什么?")
embedded_query[:5][0.0053587136790156364,
-0.0004999046213924885,
0.038883671164512634,
-0.003001077566295862,
-0.00900818221271038]向量存储
:::🗒️ 请前往Integrations查看内置与第三方向量存储集成的文档。 :::
存储和搜索非结构化数据的最常见方式之一是将其嵌入并存储生成的嵌入向量,然后在查询时嵌入非结构化查询并检索与嵌入查询“最相似”的嵌入向量。向量存储负责存储嵌入数据并为您执行向量搜索。
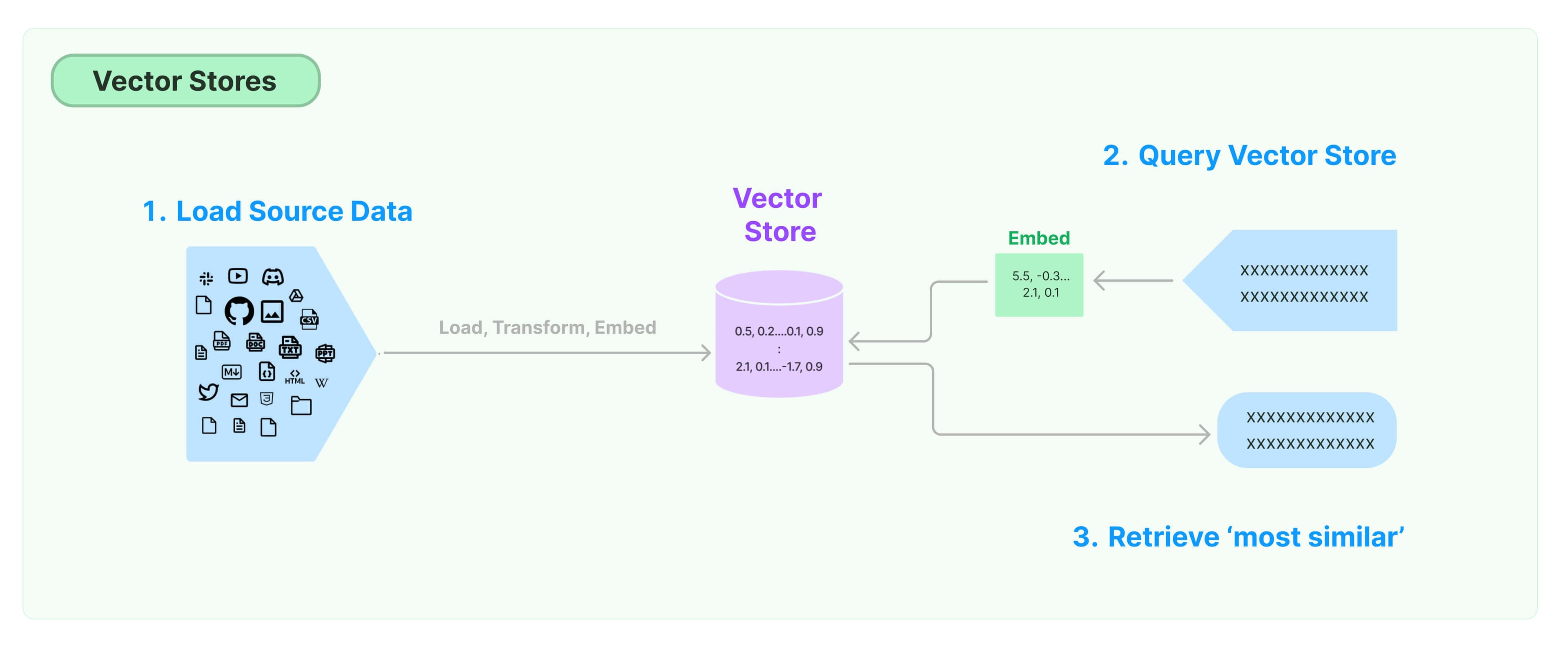
入门
本教程展示了与向量存储相关的基本功能。使用向量存储的关键部分是创建要放入向量存储中的向量,通常是通过嵌入创建的。因此,建议您在深入研究本教程之前先熟悉文本嵌入模型接口。
import Tabs from '@theme/Tabs'; import TabItem from '@theme/TabItem';
有许多出色的向量存储选项,以下是一些免费的、开源的向量存储选项,完全在您的本地计算机上运行。查看所有集成以获取许多出色的托管服务。
此教程使用chroma向量数据库,在本地计算机上作为库运行。
pip install chromadb我们希望使用OpenAI Embeddings,因此我们需要获取OpenAI API密钥。
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
# 加载文档,将其分成块,对每个块进行嵌入,然后将其加载到向量存储中。
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())此教程使用FAISS向量数据库,使用Facebook AI Similarity Search (FAISS)库。
pip install faiss-cpu我们希望使用OpenAI Embeddings,因此我们需要获取OpenAI API密钥。
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
# 加载文档,将其分成块,对每个块进行嵌入,然后将其加载到向量存储中。
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())本笔记展示了与基于Lance数据格式的LanceDB向量数据库相关的功能。
pip install lancedb我们希望使用OpenAI Embeddings,因此我们需要获取OpenAI API密钥。
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"my_table",
data=[
{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}
],
mode="overwrite",
)
# 加载文档,将其分成块,对每个块进行嵌入,然后将其加载到向量存储中。
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings())相似性搜索
query = "总统对Ketanji Brown Jackson说了什么"
docs = db.similarity_search(query)
print(docs[0].page_content) 今晚。我呼吁参议院:通过“自由投票法案”。通过“约翰·刘易斯投票权法案”。并且在您这样做的时候通过“披露法案”以便美国人知道是谁在资助我们的选举。
今晚,我想向一个一直致力于为这个国家服务的人致敬:司法部长斯蒂芬·布雷耶-一位陆军退伍军人、宪法学者和美国最高法院即将退休的法官。布雷耶法官,感谢您的服务。
总统的一个最严肃的宪法责任就是任命一个人担任美国最高法院的法官。
而我在4天前也做了,我提名了巡回上诉法院法官Ketanji Brown Jackson。她是我国顶尖的法律精英,将继续布雷耶法官卓越的遗产。基于向量的相似性搜索
还可以使用similarity_search_by_vector搜索与给定嵌入向量相似的文档,该函数接受嵌入向量作为参数而不是字符串。
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)查询是相同的,因此结果也相同。
今晚。我呼吁参议院:通过“自由投票法案”。通过“约翰·刘易斯投票权法案”。并且在您这样做的时候通过“披露法案”以便美国人知道是谁在资助我们的选举。
今晚,我想向一个一直致力于为这个国家服务的人致敬:司法部长斯蒂芬·布雷耶-一位陆军退伍军人、宪法学者和美国最高法院即将退休的法官。布雷耶法官,感谢您的服务。
总统的一个最严肃的宪法责任就是任命一个人担任美国最高法院的法官。
而我在4天前也做了,我提名了巡回上诉法院法官Ketanji Brown Jackson。她是我国顶尖的法律精英,将继续布雷耶法官卓越的遗产。异步操作
向量存储通常作为一个需要一些IO操作的独立服务运行,因此可能会被异步调用。这样可以获得性能优势,因为不必等待来自外部服务的响应。如果您使用类似FastAPI (opens in a new tab)的异步框架,这一点也可能很重要。
LangChain支持向量存储上的异步操作。所有方法都可以使用其带有前缀a的异步对应方法调用,表示async。
Qdrant是一个支持所有异步操作的向量存储,因此在本教程中将使用它。
pip install qdrant-clientfrom langchain_community.vectorstores import Qdrant异步创建向量存储
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")相似性搜索
query = "总统对Ketanji Brown Jackson说了什么"
docs = await db.asimilarity_search(query)
print(docs[0].page_content) 今晚。我呼吁参议院:通过“自由投票法案”。通过“约翰·刘易斯投票权法案”。并且在您这样做的时候通过“披露法案”以便美国人知道是谁在资助我们的选举。
今晚,我想向一个一直致力于为这个国家服务的人致敬:司法部长斯蒂芬·布雷耶-一位陆军退伍军人、宪法学者和美国最高法院即将退休的法官。布雷耶法官,感谢您的服务。
总统的一个最严肃的宪法责任就是任命一个人担任美国最高法院的法官。
而我在4天前也做了,我提名了巡回上诉法院法官Ketanji Brown Jackson。她是我国顶尖的法律精英,将继续布雷耶法官卓越的遗产。基于向量的相似性搜索
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)最大边际相关性搜索 (MMR)
最大边际相关性搜索优化了与查询的相似性和所选文档之间的多样性。异步API也支持这一点。
query = "总统对Ketanji Brown Jackson说了什么"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")1. 今晚。我呼吁参议院:通过“自由投票法案”。通过“约翰·刘易斯投票权法案”。并且在您这样做的时候通过“披露法案”以便美国人知道是谁在资助我们的选举。
今晚,我想向一个一直致力于为这个国家服务的人致敬:司法部长斯蒂芬·布雷耶-一位陆军退伍军人、宪法学者和美国最高法院即将退休的法官。布雷耶法官,感谢您的服务。
总统的一个最严肃的宪法责任就是任命一个人担任美国最高法院的法官。
而我在4天前也做了,我提名了巡回上诉法院法官Ketanji Brown Jackson。她是我国顶尖的法律精英,将继续布雷耶法官卓越的遗产。
2. 我们不能改变我们之间的分歧。但我们可以改变我们如何共同前进-在COVID-19和必须共同面对的其他问题上。
不久前,我在纽约市警察局让后在警官Wilbert Mora和他的搭档警官Jason Rivera的葬礼后几天造访了。他们在响应一个911电话时,一个男子用一把偷来的枪射杀了他们。
莫拉警官27岁。
里维拉警官22岁。
两位多米尼加裔美国人,他们在同一条街道长大,后来选择作为警察巡逻。
我和他们的家人交谈,并告诉他们,我们永远要对他们的牺牲感激,我们将继续履行他们恢复每个社区应得的信任和安全使命。
我一直在关注这些问题很久了。
我知道什么管用:投资于犯罪预防和社区警察官员,他们会巡逻,会了解社区,会恢复信任和安全。核心模块简介
LangChain为以下主要组件提供标准、可扩展的接口和外部集成:
模型I/O
格式化和管理语言模型的输入和输出
提示
用于指导生成的LLM输出的格式化
聊天模型
使用聊天消息作为输入并将聊天消息作为输出返回的语言模型的接口(而不是使用普通文本)。
LLMs
使用普通文本作为输入和输出的语言模型的接口
检索
与特定应用程序的数据进行接口交互,例如 RAG
文档加载器
从源加载数据作为稍后处理的"文档"
文本分割器
将源文档转换为更适合您的应用程序的格式
嵌入模型
创建文本片段的向量表示,实现自然语言搜索
向量存储
用于搜索自然语言的非结构化数据的专用数据库的接口
检索器
根据无结构查询返回文档的更通用的接口
组成
将其他任意系统和/或LangChain原语组合在一起的高级组件
工具
允许LLM与外部系统交互的接口
代理
根据高级指令选择要使用的工具的构建块
链
由其他可运行组件构建的模块化组合
附加功能
存储
在链的多次运行之间持久化应用程序状态
回调
记录和流式传输任何链的中间步骤
聊天消息
:::🗒️ 请前往Integrations查看有关内置内存集成与第三方数据库和工具的文档。 :::
一个核心实用类,支持大多数(如果不是全部)内存模块的基础是ChatMessageHistory类。
这是一个超级轻量级的包装器,提供方便的方法来保存HumanMessages、AIMessages,然后获取它们所有。
如果您在链外管理内存,可能会直接使用这个类。
from langchain.memory import ChatMessageHistory
history = ChatMessageHistory()
history.add_user_message("嗨!")
history.add_ai_message("最近怎么样?")history.messages [HumanMessage(content='嗨!', additional_kwargs={}),
AIMessage(content='最近怎么样?', additional_kwargs={})][Beta] Memory
大多数LLM应用程序都具有会话界面。对话的一个重要组成部分是能够提及对话中先前介绍的信息。至少,会话系统应该能够直接访问一些过去消息的窗口。更复杂的系统将需要具有一个不断更新的世界模型,这使其能够做一些事情,比如维护有关实体及其关系的信息。
我们称之为能够存储有关过去交互的信息的能力为“记忆”。LangChain提供了许多用于向系统添加记忆的实用工具。这些实用工具可以单独使用,也可以无缝地集成到链中。
LangChain中与记忆相关的大多数功能都标记为beta版。这是由于两个原因:
-
大多数功能(有些例外,请参见下文)尚未达到生产就绪状态
-
大多数功能(有些例外,请参见下文)与旧版本LCEL语法而非较新的LCEL语法兼容。
其中主要的例外是ChatMessageHistory功能。此功能基本上已经达到了生产就绪状态,并且与LCEL集成在一起。
介绍
一个记忆系统需要支持两个基本操作:读取和写入。请记住,每个链都定义了一些核心执行逻辑,期望某些输入。其中一些输入直接来自用户,但有些输入可以来自记忆。在一次运行中,链将与其记忆系统交互两次。
- 在接收到初始用户输入但在执行核心逻辑之前,链将从其记忆系统中读取信息并扩充用户输入。
- 在执行核心逻辑但在返回答案之前,链将当前运行的输入和输出写入到记忆中,以便在以后的运行中可以引用它们。
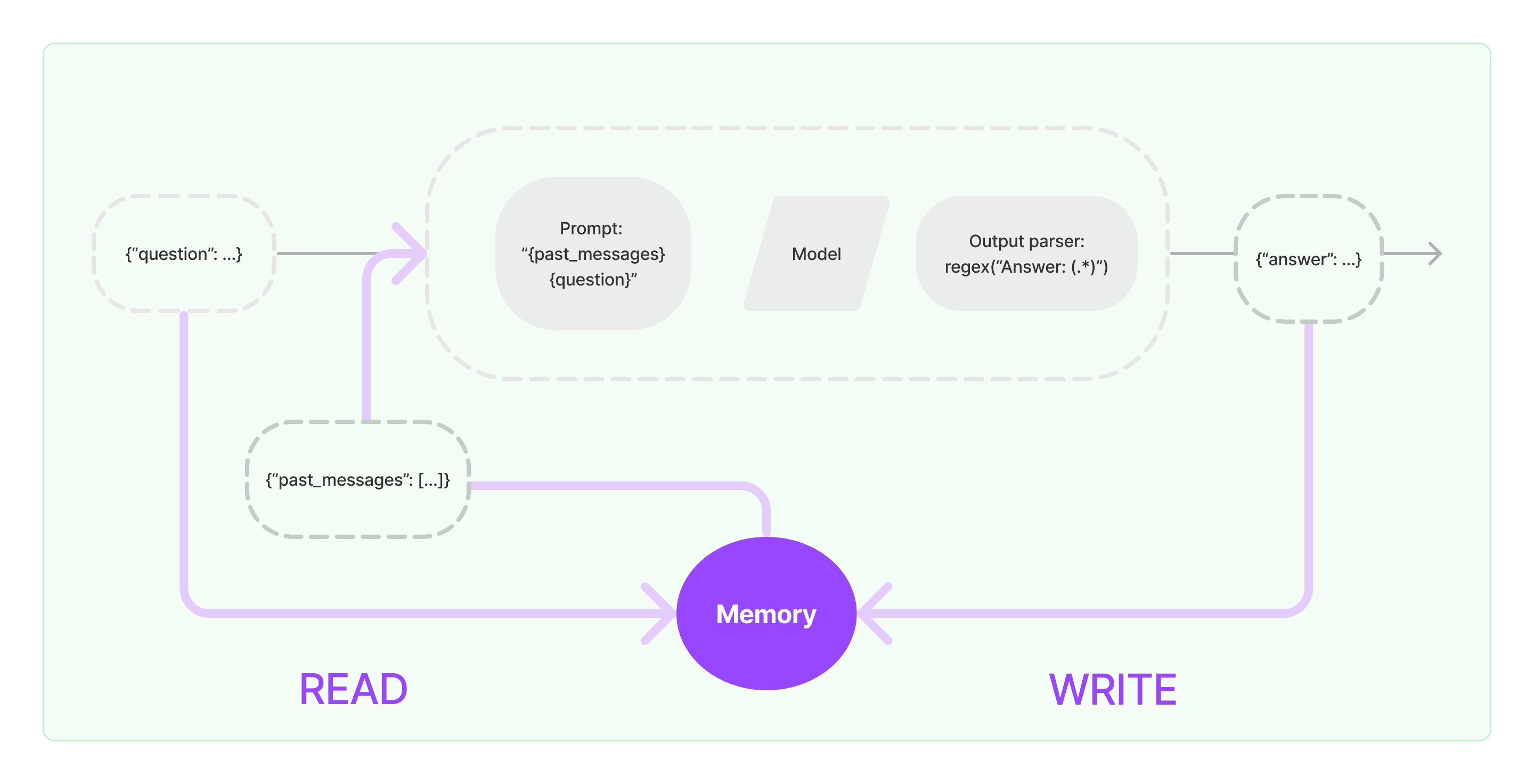
将记忆内置到系统中
任何记忆系统中的两个核心设计决策是:
- 如何存储状态
- 如何查询状态
存储:聊天消息列表
任何记忆的基础是所有聊天互动的历史记录。即使这些不是直接使用的,它们也需要以某种形式存储。LangChain记忆模块的一个关键部分是一系列用于存储这些聊天消息的集成,从内存列表到持久性数据库不等。
- 聊天消息存储: 如何处理聊天消息和提供的各种集成
查询:建立在聊天消息之上的数据结构和算法
记录聊天消息列表是相当直接的。不太直接的是建立在聊天消息之上的数据结构和算法,以提供最有用的消息视图。
一个非常简单的记忆系统可能只返回每次运行的最新消息。一个稍微更复杂的记忆系统可能返回过去K个消息的简明摘要。一个更复杂的系统可能从存储的消息中提取实体,仅返回与当前运行中引用的实体相关的信息。
每个应用程序对如何查询记忆都可能有不同的要求。记忆模块应该让简单的记忆系统易于入门,并在需要时编写自定义的系统。
- 记忆类型: LangChain支持的各种数据结构和算法
入门
让我们看一下在LangChain中记忆实际上是什么样的。在这里,我们将介绍与任意记忆类交互的基础知识。
让我们看看在链中如何使用ConversationBufferMemory。ConversationBufferMemory是一种极其简单的记忆形式,只需将聊天消息列表保存在缓冲区中,并将其传递到提示模板中。
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("hi!")
memory.chat_memory.add_ai_message("what's up?")在链中使用记忆时,有一些关键概念需要理解。请注意,这里涵盖了对大多数记忆类型都有用的一般概念。每个个别的记忆类型可能都有自己的参数和概念,需要理解。
记忆返回哪些变量
在进入链之前,会从记忆中读取各种变量。这些变量具有特定的名称,需要与链期望的变量保持一致。您可以通过调用memory.load_memory_variables({})来看到这些变量是什么。请注意,我们传入的空字典仅用作实际变量的占位符。如果您使用的记忆类型依赖于输入变量,您可能需要传入一些变量。
memory.load_memory_variables({}) {'history': "Human: hi!\nAI: what's up?"}在这种情况下,您可以看到load_memory_variables返回一个名为history的键。这意味着您的链(可能还有您的提示)应该期望一个名为history的输入。通常,您可以通过记忆类的参数来控制此变量。例如,如果要返回的记忆变量在键chat_history中,可以这样做:
memory = ConversationBufferMemory(memory_key="chat_history")
memory.chat_memory.add_user_message("hi!")
memory.chat_memory.add_ai_message("what's up?") {'chat_history': "Human: hi!\nAI: what's up?"}控制这些键的参数名称可能会因记忆类型而异,但重要的是要了解(1)这是可控的,以及(2)如何控制它。
记忆是字符串还是消息列表
其中一种最常见的记忆类型涉及返回一个聊天消息列表。这些可以作为一个字符串全部连在一起返回(当它们将被传递给LLM时很有用),或者作为一个消息列表返回(当它们将被传递给ChatModel时很有用)。
默认情况下,它们被作为一个字符串返回。为了返回一个消息列表,您可以设置return_messages=True
memory = ConversationBufferMemory(return_messages=True)
memory.chat_memory.add_user_message("hi!")
memory.chat_memory.add_ai_message("what's up?") {'history': [HumanMessage(content='hi!', additional_kwargs={}, example=False),
AIMessage(content='what's up?', additional_kwargs={}, example=False)]}保存到记忆的键是什么
通常情况下,链接收或返回多个输入/输出键。在这些情况下,我们如何知道想要保存到聊天消息历史记录中的哪些键?这通常可以通过记忆类型上的input_key和output_key参数来控制。
这些参数默认为None - 如果只有一个输入/输出键,则可以直接使用。但是,如果存在多个输入/输出键,则必须指定要使用的名称。
端到端示例
最后,让我们看一下在链中如何使用这些内容。我们将使用LLMChain,并展示如何使用LLM和ChatModel。
使用LLM
from langchain_openai import OpenAI
from langchain_core.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = OpenAI(temperature=0)
# 注意“chat_history”出现在提示模板中
template = """You are a nice chatbot having a conversation with a human.
Previous conversation:
{chat_history}
New human question: {question}
Response:"""
prompt = PromptTemplate.from_template(template)
# 注意我们需要对齐`memory_key`
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)# 注意我们只传入`question`变量 - `chat_history`将由记忆填充
conversation({"question": "hi"})使用ChatModel
from langchain_openai import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# 这里的`variable_name`必须与记忆对齐
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# 注意我们`return_messages=True`以适应MessagesPlaceholder
# 注意`"chat_history"`与MessagesPlaceholder名称对齐。
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)# 注意我们只传入`question`变量 - `chat_history`将由记忆填充
conversation({"question": "hi"})下一步
这就是入门的全部内容!请查看其他部分,了解更高级主题的演练,如自定义记忆、多个记忆等等。
记忆类型
有许多不同类型的内存。 每种类型都有自己的参数,自己的返回类型,并且在不同情况下都是有用的。 请查看它们各自的页面,以获取更多关于每种类型的详细信息。# 聊天模型
聊天模型是LangChain的核心组件。
聊天模型是一种语言模型,它以聊天消息作为输入,并返回聊天消息作为输出(而不是使用纯文本)。
LangChain与许多模型提供商(OpenAI、Cohere、Hugging Face等)集成,并公开了一个标准接口,用于与所有这些模型进行交互。
LangChain允许您以同步、异步、批处理和流模式使用模型,并提供其他功能(例如缓存)等等。
快速入门
查看这个快速入门以获取有关如何使用ChatModels的概述,包括它们提供的所有不同方法
集成
要查看LangChain提供的所有LLM集成的完整列表,请转到集成页面
如何指南
我们有几篇如何指南,用于更高级地使用LLM。 其中包括:
- 如何缓存ChatModel响应
- 如何使用支持函数调用的ChatModels
- 如何从ChatModel中流式传输响应
- 如何跟踪ChatModel调用中的令牌使用情况
- 如何创建自定义ChatModel =======# 模型输入与输出(Model I/O)
任何语言模型应用的核心要素是...模型。LangChain为你提供了与任何语言模型进行接口的基本组件。
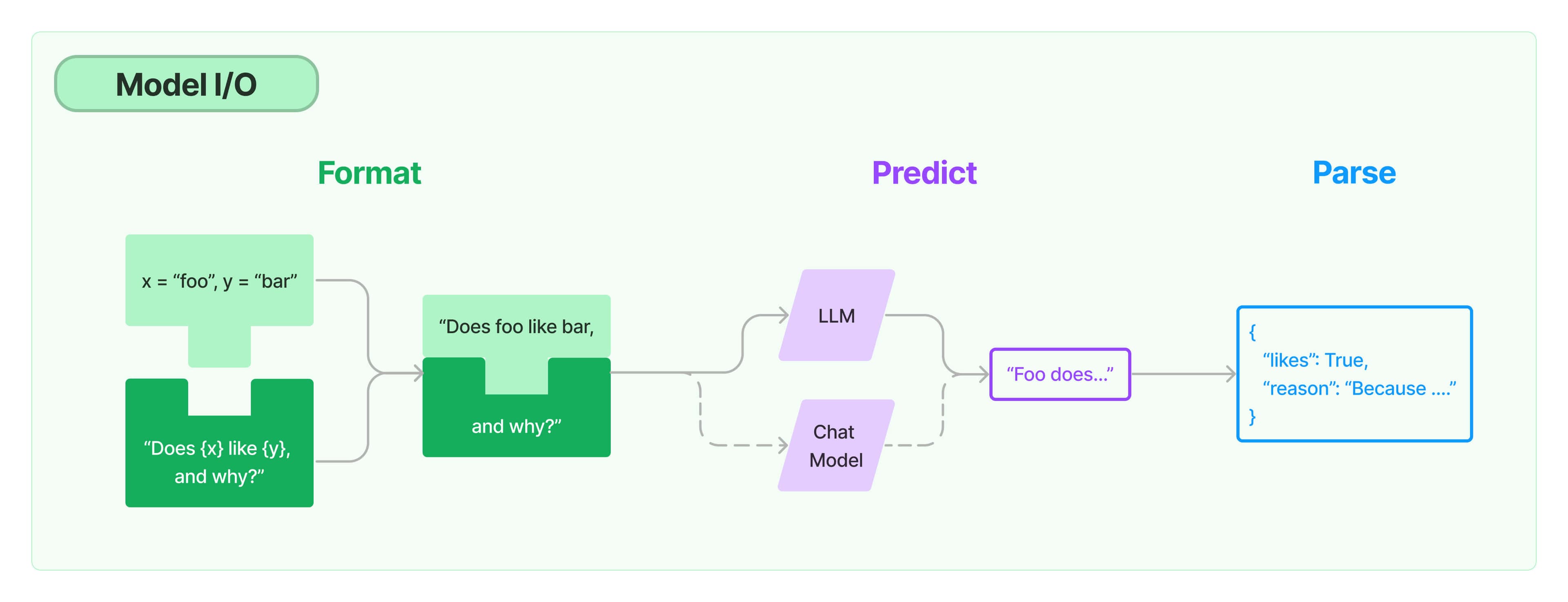
快速入门
以下快速入门将介绍如何使用LangChain的模型I/O组件的基础知识。将介绍两种不同类型的模型 - 语言模型(LLMs)和聊天模型(Chat Models)。然后将介绍如何使用提示模板来格式化这些模型的输入,以及如何使用输出解析器来处理输出。
LangChain中的语言模型有两种类型:
聊天模型
聊天模型通常由LLMs支持,但专门用于进行对话。 关键是,它们的提供者API使用的是与纯文本完成模型不同的接口。它们不是接收单个字符串作为输入,而是接收一个聊天消息列表作为输入,然后返回一个AI消息作为输出。有关消息的具体内容,请参阅下面的部分。GPT-4和Anthropic的Claude-2都作为聊天模型实现。
LLMs
LangChain中的LLMs指的是纯文本完成模型。 它们包装的API接受一个字符串提示作为输入,并输出一个字符串完成。OpenAI的GPT-3是作为LLM实现的。
这两种API类型具有不同的输入和输出模式。
此外,并非所有模型都是相同的。不同的模型对于最适合它们的提示策略也有所不同。例如,Anthropic的模型最适合使用XML,而OpenAI的模型最适合使用JSON。在设计应用程序时,您应该记住这一点。
对于这个入门指南,我们将使用聊天模型,并提供几个选项:使用诸如Anthropic或OpenAI之类的API,或者使用通过Ollama使用本地开源模型。
首先,我们需要安装他们的合作伙伴软件包:
pip install langchain-openai访问API需要一个API密钥,可以通过创建帐户并导航到这里 (opens in a new tab)获取密钥。一旦我们有了密钥,我们要将其设置为环境变量运行:
export OPENAI_API_KEY="..."然后我们可以初始化模型:
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAI
llm = OpenAI()
chat_model = ChatOpenAI(model="gpt-3.5-turbo-0125")如果您不想设置环境变量,可以在初始化OpenAI LLM类时直接通过api_key命名参数传递密钥:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(api_key="...")llm和chat_model都是表示特定模型配置的对象。
你可以使用诸如temperature等参数对它们进行初始化,并将它们传递给其他对象。
它们之间的主要区别是它们的输入和输出模式。
LLM对象接受字符串作为输入并输出字符串。
ChatModel对象将聊天消息列表作为输入,并输出消息。
当我们调用它们时,我们可以看到LLM和ChatModel之间的区别。
from langchain_core.messages import HumanMessage
text = "What would be a good company name for a company that makes colorful socks?"
messages = [HumanMessage(content=text)]
llm.invoke(text)
# >> Feetful of Fun
chat_model.invoke(messages)
# >> AIMessage(content="Socks O'Color")LLM返回一个字符串,而ChatModel返回一个消息。
Ollama (opens in a new tab)允许您在本地运行开源大型语言模型,例如Llama 2。
首先,按照这些说明 (opens in a new tab)设置和运行本地Ollama实例:
- 下载 (opens in a new tab)
- 通过
ollama pull llama2获取模型
然后,确保Ollama服务器正在运行。然后,您可以执行以下操作:
from langchain_community.llms import Ollama
from langchain_community.chat_models import ChatOllama
llm = Ollama(model="llama2")
chat_model = ChatOllama()llm和chat_model都是表示特定模型配置的对象。
您可以使用诸如temperature等参数对它们进行初始化,并将它们传递给其他对象。
它们之间的主要区别是它们的输入和输出模式。
LLM对象接受字符串作为输入并输出字符串。
ChatModel对象将聊天消息列表作为输入,并输出消息。
当我们调用它们时,我们可以看到LLM和ChatModel之间的区别。
from langchain_core.messages import HumanMessage
text = "What would be a good company name for a company that makes colorful socks?"
messages = [HumanMessage(content=text)]
llm.invoke(text)
# >> Feetful of Fun
chat_model.invoke(messages)
# >> AIMessage(content="Socks O'Color")LLM返回一个字符串,而ChatModel返回一个消息。
首先我们需要导入LangChain x Anthropic软件包。
pip install langchain-anthropic访问API需要一个API密钥,可以通过这里 (opens in a new tab)创建帐户来获取密钥。一旦我们有了密钥,我们要将其设置为环境变量运行:
export ANTHROPIC_API_KEY="..."然后我们可以初始化模型:
from langchain_anthropic import ChatAnthropic
chat_model = ChatAnthropic(model="claude-3-sonnet-20240229", temperature=0.2, max_tokens=1024)如果您不想设置环境变量,可以在初始化Anthropic Chat Model类时直接通过api_key命名参数传递密钥:
chat_model = ChatAnthropic(api_key="...")首先我们需要安装他们的合作伙伴软件包:
pip install langchain-cohere访问API需要一个API密钥,可以通过创建帐户并导航到这里 (opens in a new tab)获取密钥。一旦我们有了密钥,我们要将其设置为环境变量运行:
export COHERE_API_KEY="..."然后我们可以初始化模型:
from langchain_cohere import ChatCohere
chat_model = ChatCohere()如果您不想设置环境变量,可以在初始化Cohere LLM类时直接通过cohere_api_key命名参数传递密钥:
from langchain_cohere import ChatCohere
chat_model = ChatCohere(cohere_api_key="...")提示模板
大多数LLM应用程序不会直接将用户输入传递给LLM。通常,它们将用户输入添加到一个更大的文本片段中,称为提示模板,该模板为特定任务提供附加上下文。
在前面的示例中,我们传递给模型的文本包含生成公司名称的指示。对于我们的应用程序来说,如果用户只需提供公司/产品的描述而不必担心给模型指示,那将是非常棒的。
PromptTemplates可以帮助实现这一点!它们将用户输入和完全格式化的提示捆绑在一起。 这可以从非常简单的开始 - 例如,生成上述字符串的提示只会是:
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template("生成一个制作{product}的公司的产品列表。")
prompt.format(product="多彩的袜子")生成一个制作多彩的袜子的公司的产品列表。使用提示而不是原始字符串格式化具有几个优点。 您可以部分格式化变量 - 例如,您可以一次只格式化某些变量。 您可以将它们组合在一起,轻松将不同的模板组合成一个提示。 有关这些功能的说明,请参见有关提示的部分中的详细信息。
PromptTemplate还可以用于生成消息列表。
在这种情况下,提示不仅包含有关内容的信息,还包含每个消息(其角色,其在列表中的位置等)。
在这里,最常见的情况是ChatPromptTemplate是ChatMessageTemplates的列表。
每个ChatMessageTemplate包含有关如何格式化该ChatMessage的指示 - 其角色,以及其内容。
让我们在下面看一个例子:
from langchain.prompts.chat import ChatPromptTemplate
template = "您是一个有帮助的助手,可以将输入语言{input_language}翻译成输出语言{output_language}。"
human_template = "{text}"
chat_prompt = ChatPromptTemplate.from_messages([
("system", template),
("human", human_template),
])
chat_prompt.format_messages(input_language="英语", output_language="法语", text="我喜欢编程。")[
SystemMessage(content="您是一个有帮助的助手,可以将输入语言英语翻译为输出语言法语。", additional_kwargs={}),
HumanMessage(content="我喜欢编程。")
]ChatPromptTemplates还可以以其他方式构建 - 有关详细信息,请参见有关提示的部分。
输出解析器
OutputParser将语言模型的原始输出转换为可用于下游处理的格式。
OutputParser有几种主要类型,包括:
- 将来自
LLM的文本转换为结构化信息(例如JSON) - 将
ChatMessage转换为纯字符串 - 将除消息以外的额外信息(例如OpenAI函数调用)转换为字符串。
有关详细信息,请参阅关于输出解析器的部分。
在这个入门指南中,我们使用了一个解析逗号分隔值列表的简单输出解析器。
from langchain.output_parsers import CommaSeparatedListOutputParser
output_parser = CommaSeparatedListOutputParser()
output_parser.parse("你好,再见")
# >> ['你好', '再见']与LCEL组合
现在我们可以将所有这些组合成一个链式调用。 这个链式调用将获取输入变量,将其传递给提示模板创建提示,将提示传递给语言模型,然后将输出通过(可选的)输出解析器进行处理。 这是一种方便的方式来捆绑一个模块化逻辑块。 让我们看看它的实际应用!
template = "生成一个{num}个[对象]的列表。\n\n{format_instructions}"
chat_prompt = ChatPromptTemplate.from_template(template)
chat_prompt = chat_prompt.partial(format_instructions=output_parser.get_format_instructions())
chain = chat_prompt | chat_model | output_parser
chain.invoke({"num": 5})
# >> ['red', 'blue', 'green', 'yellow', 'orange']请注意,我们使用|语法将这些组件连接在一起。
这种|语法是由LangChain Expression Language(LCEL)提供支持的,并依赖所有这些对象实现的通用Runnable接口。
要了解有关LCEL的更多信息,请阅读这里的文档。
结论
这就是关于提示,模型和输出解析器入门的全部内容!这只是涵盖了学习的一部分。要获取更多信息,请查看:
- 提示部分以获取有关如何使用提示模板的信息
- ChatModel部分以获取有关ChatModel接口的更多信息
- LLM部分以获取有关LLM接口的更多信息
- 输出解析器部分以获取有关不同类型输出解析器的信息。# LLMs
大型语言模型(LLMs)是LangChain的核心组件。 LangChain并不提供自己的LLMs,而是为与许多不同的LLMs进行交互提供了一个标准接口。具体来说,该接口将字符串作为输入并返回一个字符串。
有许多LLM提供商(OpenAI、Cohere、Hugging Face等)- LLM 类的设计旨在为它们提供一个标准接口。
快速入门
查看此快速入门,了解如何使用LLMs,包括它们提供的所有不同方法
集成
要查看LangChain提供的所有LLM集成的完整列表,请访问集成页面
操作指南
我们有几个操作指南,用于更高级的LLMs使用。 其中包括:
- 如何编写自定义LLM类
- 如何缓存LLM响应
- 如何从LLM中流式传输响应
- 如何跟踪LLM调用中的令牌使用情况 =======# 输出解析器
输出解析器负责接收LLM的输出并将其转换为更合适的格式。当您使用LLM生成任何形式的结构化数据时,这将非常有用。
除了拥有大量不同类型的输出解析器之外,LangChain OutputParsers的一个突出优点是许多解析器支持流式处理。
快速入门
查看此快速入门指南了解输出解析器的简介以及如何使用它们。
输出解析器类型
LangChain拥有许多不同类型的输出解析器。以下是LangChain支持的输出解析器清单。下表包含各种信息:
- 名称:输出解析器的名称
- 支持流式处理:输出解析器是否支持流式处理。
- 具有格式说明:输出解析器是否具有格式说明。通常是可用的,除非(a)所需模式未在提示中指定,而是在其他参数中指定(如OpenAI函数调用);或者(b)当OutputParser包装另一个OutputParser时。
- 调用LLM:此输出解析器本身是否调用LLM。这通常仅由尝试纠正格式错误的输出解析器执行。
- 输入类型:预期的输入类型。大多数输出解析器适用于字符串和消息,但某些输出解析器(如OpenAI函数)需要具有特定kwargs的消息。
- 输出类型:解析器返回的对象的输出类型。
- 描述:我们对该输出解析器的评论以及何时使用它。
| 名称 | 支持流式处理 | 具有格式说明 | 调用LLM | 输入类型 | 输出类型 | 描述 |
|---|---|---|---|---|---|---|
| OpenAITools | (向模型传递tools) | 带tool_choice的Message | JSON对象 | 使用最新的OpenAI函数调用参数tools和tool_choice来构造返回输出。如果您正在使用支持函数调用的模型,则这通常是最可靠的方法。 | ||
| OpenAIFunctions | ✅ | (向模型传递functions) | 带function_call的Message | JSON对象 | 使用旧版OpenAI函数调用参数functions和function_call来构造返回输出。 | |
| JSON | ✅ | ✅ | str | Message | JSON对象 | 根据指定返回JSON对象。您可以指定一个Pydantic模型,它将返回该模型的JSON。对于获取不使用函数调用的结构化数据,这可能是最可靠的输出解析器。 | |
| XML | ✅ | ✅ | str | Message | dict | 返回标记的字典。需要XML输出时使用。与擅长编写XML的模型(如Anthropic的模型)一起使用。 | |
| CSV | ✅ | ✅ | str | Message | List[str] | 返回逗号分隔值的列表。 | |
| OutputFixing | ✅ | str | Message | 包装另一个输出解析器。如果该输出解析器出现错误,则此解析器将传递错误消息和错误输出给LLM,并要求它修复输出。 | |||
| RetryWithError | ✅ | str | Message | 包装另一个输出解析器。如果该输出解析器出现错误,则此解析器将传递原始输入、错误输出和错误消息给LLM,并要求其修复。与OutputFixingParser相比,此解析器还会发送原始指令。 | |||
| Pydantic | ✅ | str | Message | pydantic.BaseModel | 接受用户定义的Pydantic模型,并以该格式返回数据。 | ||
| YAML | ✅ | str | Message | pydantic.BaseModel | 接受用户定义的Pydantic模型,并以该格式返回数据。使用YAML对其进行编码。 | ||
| PandasDataFrame | ✅ | str | Message | dict | 用于在pandas DataFrames上执行操作。 | ||
| Enum | ✅ | str | Message | Enum | 将响应解析为提供的枚举值之一。 | ||
| Datetime | ✅ | str | Message | datetime.datetime | 将响应解析为日期时间字符串。 | ||
| Structured | ✅ | str | Message | Dict[str, str] | 一个返回结构化信息的输出解析器。与其他输出解析器相比,它的功能较弱,因为它只允许字段为字符串。当您使用较小的LLM时,这可能是有用的。 |
如果您有大量示例,可能需要选择要包含在提示中的示例。 示例选择器是负责执行此操作的类。
基础接口定义如下:
class BaseExampleSelector(ABC):
"""选择提示中要包含的示例的接口。"""
@abstractmethod
def select_examples(self, input_variables: Dict[str, str]) -> List[dict]:
"""根据输入选择要使用的示例。"""
@abstractmethod
def add_example(self, example: Dict[str, str]) -> Any:
"""将新示例添加到存储。"""唯一需要定义的方法是select_examples方法。此方法接受输入变量,然后返回一个示例列表。每个具体实现的示例选择方式可能不同。
LangChain具有几种不同类型的示例选择器。要查看所有这些类型的概述,请参见下表。
在本指南中,我们将介绍如何创建自定义示例选择器。
示例
为了使用示例选择器,我们需要创建一个示例列表。这些通常应为示例输入和输出。为此演示目的,让我们假设我们正在选择如何将英语翻译为意大利语的示例。
examples = [
{"input": "hi", "output": "ciao"},
{"input": "bye", "output": "arrivaderci"},
{"input": "soccer", "output": "calcio"},
]自定义示例选择器
让我们编写一个示例选择器,根据单词长度选择所选示例。
from langchain_core.example_selectors.base import BaseExampleSelector
class CustomExampleSelector(BaseExampleSelector):
def __init__(self, examples):
self.examples = examples
def add_example(self, example):
self.examples.append(example)
def select_examples(self, input_variables):
# 这假设知道输入的一部分将是一个 'text' 键
new_word = input_variables["input"]
new_word_length = len(new_word)
# 初始化变量以存储最佳匹配及其长度差异
best_match = None
smallest_diff = float("inf")
# 遍历每个示例
for example in self.examples:
# 计算第一个示例单词的长度差异
current_diff = abs(len(example["input"]) - new_word_length)
# 如果当前示例在长度上更接近,则更新最佳匹配
if current_diff < smallest_diff:
smallest_diff = current_diff
best_match = example
return [best_match]example_selector = CustomExampleSelector(examples)example_selector.select_examples({"input": "okay"})[{'input': 'bye', 'output': 'arrivaderci'}]example_selector.add_example({"input": "hand", "output": "mano"})example_selector.select_examples({"input": "okay"})[{'input': 'hand', 'output': 'mano'}]在提示中使用
我们现在可以在提示中使用此示例选择器
from langchain_core.prompts.few_shot import FewShotPromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
example_prompt = PromptTemplate.from_template("Input: {input} -> Output: {output}")prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="Input: {input} -> Output:",
prefix="将以下单词从英语翻译为意大利语:",
input_variables=["input"],
)
print(prompt.format(input="word"))输出如下:
将以下单词从英语翻译为意大利语:
Input: hand -> Output: mano
Input: word -> Output:
示例选择器类型
| 名称 | 描述 |
|---|---|
| 相似度 | 使用输入和示例之间的语义相似性来决定选择哪些示例。 |
| MMR | 使用输入和示例之间的最大边际相关性来决定选择哪些示例。 |
| 长度 | 根据可以适应在特定长度内的示例数量选择示例。 |
| Ngram | 使用输入和示例之间的ngram重叠来决定选择哪些示例。 |
提示
语言模型的提示是用户提供的一组指令或输入,用于引导模型的响应,帮助它理解上下文并生成相关和连贯的基于语言的输出,比如回答问题、完成句子或参与对话。
快速入门
这个快速入门提供了如何使用提示的基本概述。
操作指南
我们有许多操作指南,介绍如何使用提示。包括:
示例选择器类型
LangChain有几种不同类型的示例选择器可供使用。你可以在这里探索这些类型。 here =======# 工具
工具是代理、链或LLM可以用来与世界互动的接口。它们结合了几个要素:
- 工具的名称
- 工具是什么的描述
- 工具输入的JSON模式
- 要调用的函数
- 工具的结果是否应直接返回给用户
拥有所有这些信息对于建立行动系统非常有用!名称、描述和JSON模式可用于提示LLM,这样它就知道如何指定要采取的行动,然后调用的函数相当于执行该操作。
工具的输入越简单,LLM就越容易使用它。 许多代理只能使用具有单个字符串输入的工具。 有关代理类型以及哪些代理适用于更复杂输入的列表,请参阅此文档
重要的是,名称、描述和JSON模式(如果使用)都在提示中使用。因此,很重要的是它们清晰并准确描述工具的使用方式。如果LLM不明白如何使用工具,则可能需要更改默认名称、描述或JSON模式。
默认工具
让我们看看如何使用工具。为此,我们将使用内置工具。
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper现在我们初始化工具。这里我们可以根据需要配置工具
api_wrapper = WikipediaAPIWrapper(top_k_results=1, doc_content_chars_max=100)
tool = WikipediaQueryRun(api_wrapper=api_wrapper)这是默认名称
tool.name'Wikipedia'
这是默认描述
tool.description'A wrapper around Wikipedia. Useful for when you need to answer general questions about people, places, companies, facts, historical events, or other subjects. Input should be a search query.'
这是输入的默认JSON模式
tool.args{'query': {'title': 'Query', 'type': 'string'}}
我们可以查看工具是否应该直接返回给用户
tool.return_directFalse
我们可以使用字典输入调用此工具
tool.run({"query": "langchain"})'Page: LangChain\nSummary: LangChain is a framework designed to simplify the creation of applications '
我们还可以使用单个字符串输入调用此工具。 我们之所以能够这样做是因为此工具仅期望单个输入。 如果需要多个输入,则无法这样做。
tool.run("langchain")'Page: LangChain\nSummary: LangChain is a framework designed to simplify the creation of applications '
自定义默认工具
我们还可以修改内置名称、描述和参数的JSON模式。
在定义参数的JSON模式时,重要的是输入保持与函数相同,因此您不应更改它。但您可以轻松为每个输入定义自定义描述。
from langchain_core.pydantic_v1 import BaseModel, Field
class WikiInputs(BaseModel):
"""Wikipedia工具的输入。"""
query: str = Field(
description="在维基百科查找的查询,应为3个单词或更少"
)tool = WikipediaQueryRun(
name="wiki-tool",
description="在维基百科查找东西",
args_schema=WikiInputs,
api_wrapper=api_wrapper,
return_direct=True,
)tool.name'wiki-tool'
tool.description'在维基百科查找东西'
tool.args{'query': {'title': 'Query', 'description': '在维基百科查找的查询,应为3个单词或更少', 'type': 'string'}}
tool.return_directTrue
tool.run("langchain")'Page: LangChain\nSummary: LangChain is a framework designed to simplify the creation of applications '
更多主题
这是 LangChain 工具的简要介绍,但还有很多内容可以学习
自定义工具: 尽管内置工具很有用,但很可能您需要定义自己的工具。请参阅此指南了解如何操作。
工具包: 工具包是一组功能良好的工具集合。如需更详细描述和所有内置工具包的列表,请参阅此页面
工具作为 OpenAI 函数: 工具与 OpenAI 函数非常相似,可以轻松转换为该格式。请参阅此笔记本了解如何操作。