快速入门
概述
我们将演示如何设计和实现一个基于LLM的聊天机器人的示例。下面是我们将使用的高级组件:
聊天模型。聊天机器人的界面是基于消息而不是原始文本,因此最适合使用聊天模型而不是文本LLM。这里列出了聊天模型的集成列表,这里提供了关于LangChain中聊天模型界面的文档。您也可以使用LLM(参见这里)来创建聊天机器人,但聊天模型更适合具有对话性质和本地支持消息界面的功能。提示模板,简化了组装提示的过程,这些提示结合了默认消息、用户输入、聊天历史记录和(可选)其他检索到的上下文。聊天历史记录,允许聊天机器人“记住”过去的交互并在回答后续问题时考虑它们。详细信息请参阅这里。检索器(可选),如果您想构建一个可以使用特定领域的最新知识作为上下文来增强其响应的聊天机器人,这将非常有用。详细信息请参阅这里。
我们将介绍如何将上述组件组合在一起,创建一个强大的对话型聊天机器人。
快速入门
首先,让我们安装一些依赖项并设置所需的凭据:
%pip install --upgrade --quiet langchain langchain-openai
# 设置环境变量 OPENAI_API_KEY 或从 .env 文件中加载:
import dotenv
dotenv.load_dotenv()[33mWARNING: You are using pip version 22.0.4; however, version 23.3.2 is available.
You should consider upgrading via the '/Users/jacoblee/.pyenv/versions/3.10.5/bin/python -m pip install --upgrade pip' command.[0m[33m
[0mNote: you may need to restart the kernel to use updated packages.
True让我们初始化聊天模型,它将作为聊天机器人的核心:
from langchain_openai import ChatOpenAI
chat = ChatOpenAI(model="gpt-3.5-turbo-1106", temperature=0.2)如果调用聊天模型,输出将是一个 AIMessage:
from langchain_core.messages import HumanMessage
chat.invoke(
[
HumanMessage(
content="Translate this sentence from English to French: I love programming."
)
]
)AIMessage(content="J'adore programmer.")模型本身没有任何状态的概念。 例如,如果你问一个后续问题:
chat.invoke([HumanMessage(content="What did you just say?")])AIMessage(content='I said, "What did you just say?"')我们可以看到它没有把之前的对话转换为上下文,并且无法回答这个问题。
为了解决这个问题,我们需要将整个对话历史记录传递给模型。让我们看看当我们这样做时会发生什么:
from langchain_core.messages import AIMessage
chat.invoke(
[
HumanMessage(
content="Translate this sentence from English to French: I love programming."
),
AIMessage(content="J'adore la programmation."),
HumanMessage(content="What did you just say?"),
]
)AIMessage(content='I said "J\'adore la programmation," which means "I love programming" in French.')现在我们可以看到我们得到了一个很好的回答!
这是聊天机器人进行对话交互的基本思想。
提示模板
让我们定义一个提示模板,以使格式化更容易一些。我们可以通过将其导入模型来创建一个链式结构:
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant. Answer all questions to the best of your ability.",
),
MessagesPlaceholder(variable_name="messages"),
]
)
chain = prompt | chat上面的 MessagesPlaceholder 将聊天消息作为 chat_history 直接插入链式结构的输入中。然后,我们可以这样调用链式结构:
chain.invoke(
{
"messages": [
HumanMessage(
content="Translate this sentence from English to French: I love programming."
),
AIMessage(content="J'adore la programmation."),
HumanMessage(content="What did you just say?"),
],
}
)AIMessage(content='I said "J\'adore la programmation," which means "I love programming" in French.')消息历史记录
作为管理聊天历史记录的快捷方式,我们可以使用 MessageHistory 类,它负责保存和加载聊天消息。有许多内置的消息历史记录集成,可以将消息持久化到各种数据库中,但是在这个快速入门中,我们将使用一个内存中的示例消息历史记录 ChatMessageHistory。
以下是直接使用它的示例:
from langchain.memory import ChatMessageHistory
demo_ephemeral_chat_history = ChatMessageHistory()
demo_ephemeral_chat_history.add_user_message("hi!")
demo_ephemeral_chat_history.add_ai_message("whats up?")
demo_ephemeral_chat_history.messages[HumanMessage(content='hi!'), AIMessage(content='whats up?')]一旦我们这样做,我们可以将存储的消息直接作为参数传递给我们的链式结构:
demo_ephemeral_chat_history.add_user_message(
"Translate this sentence from English to French: I love programming."
)
response = chain.invoke({"messages": demo_ephemeral_chat_history.messages})
responseAIMessage(content='The translation of "I love programming" in French is "J\'adore la programmation."')demo_ephemeral_chat_history.add_ai_message(response)
demo_ephemeral_chat_history.add_user_message("What did you just say?")
chain.invoke({"messages": demo_ephemeral_chat_history.messages})AIMessage(content='I said "J\'adore la programmation," which is the French translation for "I love programming."')现在我们有了一个基本的聊天机器人!
虽然这个链式结构可以作为一个独立的聊天机器人并具有模型的内部知识,但通常会有用的是引入一些形式的检索增强生成(retrieval-augmented generation,简称RAG)以便于聚焦于领域特定知识。接下来我们将介绍这个内容。
Retrievers
我们可以设置并使用 Retriever 来为我们的聊天机器人提供领域特定的知识。为了展示这一点,让我们扩展上面创建的简单聊天机器人,以便能够回答有关 LangSmith 的问题。
我们将使用 LangSmith 文档 (opens in a new tab) 作为源材料,并将其存储到 vectorstore 以供以后检索。请注意,此示例将忽略围绕解析和存储数据源的一些细节 - 您可以在此处查看更详细的关于创建检索系统的文档。
让我们设置我们的检索器。首先,我们将安装一些必需的依赖项:
%pip install --upgrade --quiet chromadb beautifulsoup4然后,我们将使用一个文档加载器从网页中提取数据:
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://docs.smith.langchain.com/overview")
data = loader.load()接下来,我们将它分成更小的块,以便 LLM 的上下文窗口可以处理,并将其存储在向量数据库中:
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)然后,我们将这些块进行嵌入并存储在向量数据库中:
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())最后,让我们从初始化的向量数据库创建一个检索器:
# k 是要检索的块数
retriever = vectorstore.as_retriever(k=4)
docs = retriever.invoke("how can langsmith help with testing?")
docs我们可以看到,调用上面的检索器会返回一些包含有关测试的信息的 LangSmith 文档部分,我们的聊天机器人可以在回答问题时使用它们作为上下文。
处理文档
让我们修改上一个提示,以接受文档作为上下文。我们将使用 create_stuff_documents_chain (opens in a new tab) 辅助函数将所有输入文档“stuff”到提示中,该函数还方便地处理格式。我们使用 ChatPromptTemplate.from_messages 方法来格式化我们要传递给模型的消息输入,包括一个 MessagesPlaceholder,其中聊天历史消息将直接注入:
from langchain.chains.combine_documents import create_stuff_documents_chain
chat = ChatOpenAI(model="gpt-3.5-turbo-1106")
question_answering_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer the user's questions based on the below context:\n\n{context}",
),
MessagesPlaceholder(variable_name="messages"),
]
)
document_chain = create_stuff_documents_chain(chat, question_answering_prompt)我们可以使用上面检索到的原始文档来调用这个 document_chain:
from langchain.memory import ChatMessageHistory
demo_ephemeral_chat_history = ChatMessageHistory()
demo_ephemeral_chat_history.add_user_message("how can langsmith help with testing?")
document_chain.invoke(
{
"messages": demo_ephemeral_chat_history.messages,
"context": docs,
}
)太棒了!我们得到了一个从输入文档中合成的答案。
创建一个检索链
接下来,让我们将我们的检索器集成到链中。我们的检索器应该检索与我们从用户传递的最后一条消息相关的信息,因此我们提取它并将其用作获取相关文档的输入,然后将其作为 上下文 添加到当前链中。我们将 上下文 加上先前的 messages 传递到我们的文档链中生成最终答案。
我们还使用 RunnablePassthrough.assign() 方法在每次调用时传递中间步骤。这是它的样子:
from typing import Dict
from langchain_core.runnables import RunnablePassthrough
def parse_retriever_input(params: Dict):
return params["messages"][-1].content
retrieval_chain = RunnablePassthrough.assign(
context=parse_retriever_input | retriever,
).assign(
answer=document_chain,
)response = retrieval_chain.invoke(
{
"messages": demo_ephemeral_chat_history.messages,
}
)
response不错!我们的聊天机器人现在可以以对话方式回答领域特定的问题。
顺便说一下,如果您不想返回所有中间步骤,可以像这样使用 pipe 直接进入文档链而不是最后的 .assign() 调用来定义您的检索链:
retrieval_chain_with_only_answer = (
RunnablePassthrough.assign(
context=parse_retriever_input | retriever,
)
| document_chain
)
retrieval_chain_with_only_answer.invoke(
{
"messages": demo_ephemeral_chat_history.messages,
},
)demo_ephemeral_chat_history.add_ai_message(response["answer"])
demo_ephemeral_chat_history.add_user_message("tell me more about that!")
retrieval_chain.invoke(
{
"messages": demo_ephemeral_chat_history.messages,
},
)漂亮!我们的聊天机器人现在可以以对话方式回答领域特定的问题。
查询转换
在上面的示例中,当我们询问了一个跟进问题“tell me more about that!”时,你可能会注意到检索到的文档并没有直接包含有关测试的信息。这是因为我们将“tell me more about that!”原封不动地作为查询传递给了检索器。检索链中的输出仍然可以正常工作,因为文档链检索链可以根据聊天历史生成答案,但是我们可以获取更多丰富和有信息的文档:
retriever.invoke("how can langsmith help with testing?")retriever.invoke("tell me more about that!")为了解决这个常见问题,让我们添加一个“查询转换”步骤,以删除输入中的引用。我们将对我们的旧检索器进行如下封装:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableBranch
# 我们需要一个提示,将其传递给LLM以生成转换后的搜索查询
chat = ChatOpenAI(model="gpt-3.5-turbo-1106", temperature=0.2)
query_transform_prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name="messages"),
(
"user",
"根据上面的对话,生成一个搜索查询以获取与对话相关的信息。只回答查询,不要提供其他内容。",
),
]
)
query_transforming_retriever_chain = RunnableBranch(
(
lambda x: len(x.get("messages", [])) == 1,
# 如果只有一条信息,则直接将该信息的内容传递给检索器
(lambda x: x["messages"][-1].content) | retriever,
),
# 如果有多条信息,则将输入传递给LLM链以转换查询,然后再传递给检索器
query_transform_prompt | chat | StrOutputParser() | retriever,
).with_config(run_name="chat_retriever_chain")现在让我们使用这个新的query_transforming_retriever_chain重新创建我们之前的链。注意,这个新的链接受一个字典作为输入,并解析一个字符串以传递给检索器,所以我们不需要在顶层进行额外的解析:
document_chain = create_stuff_documents_chain(chat, question_answering_prompt)
conversational_retrieval_chain = RunnablePassthrough.assign(
context=query_transforming_retriever_chain,
).assign(
answer=document_chain,
)
demo_ephemeral_chat_history = ChatMessageHistory()最后,让我们来调用它:
demo_ephemeral_chat_history.add_user_message("how can langsmith help with testing?")
response = conversational_retrieval_chain.invoke(
{"messages": demo_ephemeral_chat_history.messages},
)
demo_ephemeral_chat_history.add_ai_message(response["answer"])
responsedemo_ephemeral_chat_history.add_user_message("tell me more about that!")
conversational_retrieval_chain.invoke(
{"messages": demo_ephemeral_chat_history.messages}
)现在,你知道如何构建一个可以将过去的消息和领域特定的知识集成到其生成中的对话聊天机器人。在这方面,你还可以进行许多其他优化——在以下页面上查看更多信息:
- 内存管理:这包括自动更新聊天历史记录的指南,以及修剪、汇总或以其他方式修改长对话以保持机器人的专注性。
- 检索:深入介绍如何在聊天机器人中使用不同类型的检索。
- 工具使用:如何让你的聊天机器人使用与其他API和系统交互的工具。
title: 快速入门 sidebar_position: 0
在这个快速入门中,我们将使用能够从文本中提取信息的聊天模型来进行函数/工具调用。
:::⚠⚠⚠
只有在支持函数/工具调用的模型上才能使用函数/工具调用进行提取。 :::
设置
我们将使用能够进行函数/工具调用的LLM上可用的结构化输出方法。
选择一个模型,安装相关依赖并设置API密钥!
!pip install langchain
#安装能够进行工具调用的模型
#pip 安装 langchain-openai
#pip 安装 langchain-mistralai
#pip 安装 langchain-fireworks
#为相关模型设置环境变量,或从.env文件中加载:
#导入dotenv
#dotenv.load_dotenv()模式
首先,我们需要描述我们想要从文本中提取的信息。
我们将使用Pydantic定义一个示例模式来提取个人信息。
from typing import Optional
from langchain_core.pydantic_v1 import BaseModel, Field
class Person(BaseModel):
"""关于个人的信息。"""
# ^ 实体Person的文档字符串。
# 此文档字符串将作为模式Person的描述发送给LLM,
# 它可以帮助提高提取结果。
# 请注意:
# 1. 每个字段都是`optional` —— 这允许模型在拒绝提取时返回`None`!
# 2. 每个字段都有一个`description` —— 这个描述由LLM使用。
# 有一个良好的描述可以帮助提高提取结果。
name: Optional[str] = Field(..., description="姓名")
hair_color: Optional[str] = Field(
..., description="如果已知,这是人的头发颜色"
)
height_in_meters: Optional[str] = Field(
..., description="以米为单位的身高"
)在定义模式时有两个最佳实践:
- 记录属性和模式本身:这些信息将被发送给LLM,用于提高提取信息的质量。
- 不要强迫LLM虚构信息!以上,我们对属性使用了
Optional,允许LLM在不知道答案时输出None。
:::⚠⚠⚠
为了获得最佳性能,好好记录模式并确保模型不会在没有文本中提取信息的情况下返回结果。 :::
提取器
让我们使用上面定义的模式创建一个信息提取器。
from typing import Optional
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
# 定义一个自定义提示,提供指示和任何额外的上下文。
# 1)您可以在提示模板中添加示例以提高提取质量
# 2)引入其他参数以考虑上下文(例如,包括从中提取文本的文档的元数据等)。
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"您是一种专家提取算法。仅从文本中提取相关信息。"
"如果您不知道要提取的属性的值,请返回属性的值为null。",
),
# 有关通过参考示例提高性能的说明,请参见 how-to
# MessagesPlaceholder('examples'),
("human", "{text}"),
]
)我们需要使用支持函数/工具调用的模型。
请查阅结构化输出以获取可与此API一起使用的模型列表。
from langchain_mistralai import ChatMistralAI
llm = ChatMistralAI(model="mistral-large-latest", temperature=0)
runnable = prompt | llm.with_structured_output(schema=Person)让我们来测试一下
text = "艾伦·史密斯身高6英尺,头发是金黄色。"
runnable.invoke({"text": text})::::
Person(name='艾伦·史密斯', hair_color='金黄色', height_in_meters='1.8288'):::⚠⚠⚠
提取是生成式的 🤯
LLM是生成模型,因此它们可以执行一些很酷的事情,比如即使提供的是英尺,也能正确提取出以米为单位的人物身高!
:::
多个实体
在大多数情况下,您应该提取一个实体的列表,而不是一个单独的实体。
这可以通过在彼此之间嵌套模型来轻松实现。
from typing import List, Optional
from langchain_core.pydantic_v1 import BaseModel, Field
class Person(BaseModel):
"""关于个人的信息。"""
# ^ 实体Person的文档字符串。
# 此文档字符串将作为模式Person的描述发送给LLM,
# 它可以帮助提高提取结果。
# 请注意:
# 1. 每个字段都是`optional` —— 这允许模型在拒绝提取时返回`None`!
# 2. 每个字段都有一个`description` —— 这个描述由LLM使用。
# 有一个良好的描述可以帮助提高提取结果。
name: Optional[str] = Field(..., description="姓名")
hair_color: Optional[str] = Field(
..., description="如果已知,这是人的头发颜色"
)
height_in_meters: Optional[str] = Field(
..., description="以米为单位的身高"
)
class Data(BaseModel):
"""关于人的提取数据。"""
# 创建一个模型,以便我们可以提取多个实体。
people: List[Person]:::⚠⚠⚠
提取可能不完美。请继续阅读如何使用参考示例来提高提取质量,以及查看指南部分! :::
runnable = prompt | llm.with_structured_output(schema=Data)
text = "我的名字是杰夫,我的头发是黑色的,我的身高是6英尺。安娜的头发颜色和我一样。"
runnable.invoke({"text": text})::::
Data(people=[Person(name='杰夫', hair_color=None, height_in_meters=None), Person(name='安娜', hair_color=None, height_in_meters=None)]):::⚠⚠⚠
当模式适应提取多个实体时,如果文本中没有相关信息,它还允许模型提取无实体,从而提供一个空列表。
这通常是一个好事!它允许为实体指定必需属性,而不一定要强迫模型检测到此实体。
:::
下一步
现在你已经了解了使用LangChain进行提取的基础知识,你可以继续阅读其他的操作指南:
- 添加示例: 学习如何使用参考示例来改进性能。
- 处理长文本: 如果文本超出LLM的上下文窗口怎么办?
- 处理文件: 使用LangChain文档加载器和解析器从文件(如PDF)中提取的示例。
- 使用解析方法: 使用基于提示的方法来提取不支持工具/函数调用的模型。
- 指南: 获取提取任务的良好性能的指南。# Quickstart
在本指南中,我们将介绍创建图数据库上的问答链的基本方法。这些系统将使我们能够对图数据库中的数据提出问题,并得到自然语言回答。
⚠️ 安全提示 ⚠️
构建图数据库的问答系统需要执行模型生成的图查询。这样做存在固有的风险。确保您的数据库连接权限始终尽可能地适用于链路/代理的需求。这将减轻建立模型驱动系统的风险,但并不能完全消除。有关一般安全性最佳实践,请参阅这里。
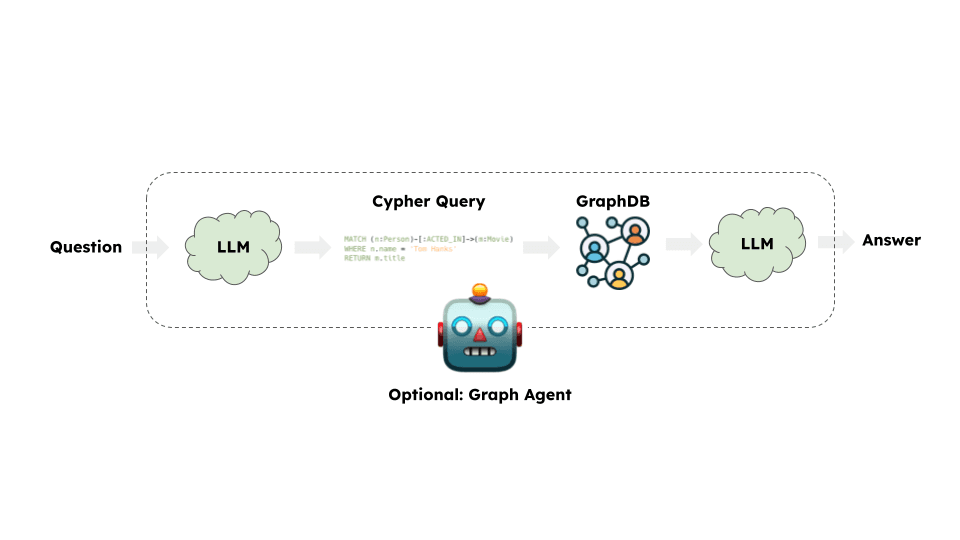
架构
从高层来看,大多数图链的步骤如下:
- 将问题转换为图数据库查询:模型将用户输入转换为图数据库查询(例如Cypher)。
- 执行图数据库查询:执行图数据库查询。
- 回答问题:模型使用查询结果回答用户的输入。
设置
首先,获取所需的软件包并设置环境变量。 在本示例中,我们将使用Neo4j图数据库。
%pip install --upgrade --quiet langchain langchain-community langchain-openai neo4j在本指南中,我们默认使用OpenAI模型。
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# 取消下面的注释以使用LangSmith。不是必需的。
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"接下来,我们需要定义Neo4j凭据。 按照安装步骤 (opens in a new tab)设置Neo4j数据库。
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "password"以下示例将创建与Neo4j数据库的连接,并使用关于电影及其演员的示例数据填充它。
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph()
# 导入电影信息
movies_query = """
LOAD CSV WITH HEADERS FROM
'https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/movies_small.csv'
AS row
MERGE (m:Movie {id:row.movieId})
SET m.released = date(row.released),
m.title = row.title,
m.imdbRating = toFloat(row.imdbRating)
FOREACH (director in split(row.director, '|') |
MERGE (p:Person {name:trim(director)})
MERGE (p)-[:DIRECTED]->(m))
FOREACH (actor in split(row.actors, '|') |
MERGE (p:Person {name:trim(actor)})
MERGE (p)-[:ACTED_IN]->(m))
FOREACH (genre in split(row.genres, '|') |
MERGE (g:Genre {name:trim(genre)})
MERGE (m)-[:IN_GENRE]->(g))
"""
graph.query(movies_query)图模式
为了使LLM能够生成Cypher语句,它需要有关图模式信息。当您实例化图对象时,它会检索有关图模式的信息。如果您稍后对图进行任何更改,则可以运行refresh_schema方法来刷新模式信息。
graph.refresh_schema()
print(graph.schema)节点属性如下所示:
Movie {imdbRating: FLOAT, id: STRING, released: DATE, title: STRING},Person {name: STRING},Genre {name: STRING},Chunk {id: STRING, question: STRING, query: STRING, text: STRING, embedding: LIST}关系属性如下所示:
(:Movie)-[:IN_GENRE]->(:Genre),(:Person)-[:DIRECTED]->(:Movie),(:Person)-[:ACTED_IN]->(:Movie)太棒了!我们有了一个可查询的图数据库。现在让我们尝试将其与LLM连接起来。
Chain
让我们使用一个简单的链,将问题转换为Cypher查询,执行查询,并使用结果回答原始问题。
LangChain附带了一个内置链,用于此工作流程,该链设计用于与Neo4j一起使用:GraphCypherQAChain
from langchain.chains import GraphCypherQAChain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
chain = GraphCypherQAChain.from_llm(graph=graph, llm=llm, verbose=True)
response = chain.invoke({"query": "What was the cast of the Casino?"})
response[1m> Entering new GraphCypherQAChain chain...[0m
Generated Cypher:
[32;1m[1;3mMATCH (:Movie {title: "Casino"})<-[:ACTED_IN]-(actor:Person)
RETURN actor.name[0m
Full Context:
[32;1m[1;3m[{'actor.name': 'Joe Pesci'}, {'actor.name': 'Robert De Niro'}, {'actor.name': 'Sharon Stone'}, {'actor.name': 'James Woods'}][0m
[1m> Finished chain.[0m{'query': 'What was the cast of the Casino?',
'result': 'The cast of Casino included Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.'}验证关系方向
LLM很难处理生成的Cypher语句中的关系方向。由于图模式是预定义的,我们可以使用validate_cypher参数来验证和可选修复生成的Cypher语句中的关系方向。
chain = GraphCypherQAChain.from_llm(
graph=graph, llm=llm, verbose=True, validate_cypher=True
)
response = chain.invoke({"query": "What was the cast of the Casino?"})
response[1m> Entering new GraphCypherQAChain chain...[0m
Generated Cypher:
[32;1m[1;3mMATCH (:Movie {title: "Casino"})<-[:ACTED_IN]-(actor:Person)
RETURN actor.name[0m
Full Context:
[32;1m[1;3m[{'actor.name': 'Joe Pesci'}, {'actor.name': 'Robert De Niro'}, {'actor.name': 'Sharon Stone'}, {'actor.name': 'James Woods'}][0m
[1m> Finished chain.[0m{'query': 'What was the cast of the Casino?',
'result': 'The cast of Casino included Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.'}下一步
对于更复杂的查询生成,我们可能希望创建few-shot prompts或添加查询检查步骤。有关这些高级技术和更多技术,请查看以下链接:
- Prompting strategies:高级提示工程技术。
- Mapping values:将问题中的值映射到数据库的技术。
- Semantic layer:实现语义层的技术。
- Constructing graphs:构建知识图谱的技术。
快速入门
这个页面将展示如何在一个基本的端到端示例中使用查询分析。这将涵盖创建一个简单的搜索引擎,展示将原始用户问题传递给搜索引擎时出现的故障模式,以及使用查询分析来解决这个问题的示例。有许多不同的查询分析技术,这个端到端示例并不会展示所有的技术。
为了这个示例,我们将在LangChain的YouTube视频上进行检索。
设置
安装依赖项
# %pip install -qU langchain langchain-community langchain-openai youtube-transcript-api pytube chromadb设置环境变量
我们将在这个示例中使用OpenAI:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# 可选的,取消注释以使用LangSmith跟踪运行结果。在此注册:https://smith.langchain.com。
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()加载文档
我们可以使用YouTubeLoader来加载一些LangChain视频的转录文本:
from langchain_community.document_loaders import YoutubeLoader
urls = [
"https://www.youtube.com/watch?v=HAn9vnJy6S4",
"https://www.youtube.com/watch?v=dA1cHGACXCo",
"https://www.youtube.com/watch?v=ZcEMLz27sL4",
"https://www.youtube.com/watch?v=hvAPnpSfSGo",
"https://www.youtube.com/watch?v=EhlPDL4QrWY",
"https://www.youtube.com/watch?v=mmBo8nlu2j0",
"https://www.youtube.com/watch?v=rQdibOsL1ps",
"https://www.youtube.com/watch?v=28lC4fqukoc",
"https://www.youtube.com/watch?v=es-9MgxB-uc",
"https://www.youtube.com/watch?v=wLRHwKuKvOE",
"https://www.youtube.com/watch?v=ObIltMaRJvY",
"https://www.youtube.com/watch?v=DjuXACWYkkU",
"https://www.youtube.com/watch?v=o7C9ld6Ln-M",
]
docs = []
for url in urls:
docs.extend(YoutubeLoader.from_youtube_url(url, add_video_info=True).load())import datetime
# 添加一些额外的元数据:视频的发布年份
for doc in docs:
doc.metadata["publish_year"] = int(
datetime.datetime.strptime(
doc.metadata["publish_date"], "%Y-%m-%d %H:%M:%S"
).strftime("%Y")
)这是我们加载的视频的标题:
[doc.metadata["title"] for doc in docs]这是每个视频的元数据。我们可以看到每个文档还有一个标题、观看次数、发布日期和长度:
docs[0].metadata这是一个文档内容的示例:
docs[0].page_content[:500]对文档进行索引
每当我们进行检索时,我们需要创建一个文档索引,以供我们查询。我们将使用一个向量存储来索引我们的文档,并且我们将首先对它们进行分块,以使我们的检索更简洁和准确:
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
chunked_docs = text_splitter.split_documents(docs)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma.from_documents(
chunked_docs,
embeddings,
)无查询分析的检索
我们可以直接对用户问题进行相似性搜索,以找到与问题相关的文本块:
search_results = vectorstore.similarity_search("how do I build a RAG agent")
print(search_results[0].metadata["title"])
print(search_results[0].page_content[:500])这效果不错!我们的第一个结果与问题相当相关。
如果我们想要搜索特定时间段内的结果呢?
search_results = vectorstore.similarity_search("videos on RAG published in 2023")
print(search_results[0].metadata["title"])
print(search_results[0].metadata["publish_date"])
print(search_results[0].page_content[:500])我们的第一个结果来自2024年(尽管我们要求搜索2023年的视频),与输入内容不相关。由于我们只是搜索文档内容,结果无法根据任何文档属性进行过滤。
这只是可能出现的一种故障模式。现在让我们看看如何使用基本的查询分析来解决这个问题!
查询分析
我们可以使用查询分析来改进检索结果。这将涉及定义一个查询模式,其中包含一些日期过滤器,并使用函数调用模型将用户问题转换为结构化查询。
查询模式
在这种情况下,我们将为发布日期设定显式的最小和最大属性,以便可以进行过滤。
from typing import Optional
from langchain_core.pydantic_v1 import BaseModel, Field
class Search(BaseModel):
"""Search over a database of tutorial videos about a software library."""
query: str = Field(
...,
description="Similarity search query applied to video transcripts.",
)
publish_year: Optional[int] = Field(None, description="Year video was published")查询生成
为了将用户的问题转换为结构化查询,我们将使用OpenAI的工具调用API。具体来说,我们将使用新的ChatModel.with_structured_output()构造函数来处理将模式传递给模型并解析输出结果。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
system = """你是将用户问题转换为数据库查询的专家。你可以访问一个关于构建基于LLM应用程序的软件库的教程视频数据库。给定一个问题,返回一系列优化检索最相关结果的数据库查询。
如果有缩略词或你不熟悉的词语,请不要尝试更改它们的措辞。"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm = llm.with_structured_output(Search)
query_analyzer = {"question": RunnablePassthrough()} | prompt | structured_llm/Users/bagatur/langchain/libs/core/langchain_core/_api/beta_decorator.py:86: LangChainBetaWarning: The function `with_structured_output` is in beta. It is actively being worked on, so the API may change.
warn_beta(
让我们看看我们的分析器为我们之前搜索的问题生成了哪些查询:
query_analyzer.invoke("我如何构建RAG代理")搜索结果输出为:
Search(query='构建 RAG 代理', publish_year=None)query_analyzer.invoke("2023年发表的RAG视频")搜索结果输出为:
Search(query='RAG', publish_year=2023)使用查询分析进行检索
我们的查询分析看起来很不错,现在让我们尝试使用生成的查询来进行实际的检索。
**注意:**在我们的示例中,我们指定了tool_choice="Search"。这将强制LLM调用一个 - 且仅调用一个 - 工具,这意味着我们将始终有一个优化的查询可供查找。请注意,这并不总是适用的情况 - 请参阅其他指南,了解在没有或有多个优化查询返回时如何处理。
from typing import List
from langchain_core.documents import Documentdef retrieval(search: Search) -> List[Document]:
if search.publish_year is not None:
# 这是特定于Chroma的语法,
# 我们使用的向量数据库。
_filter = {"publish_year": {"$eq": search.publish_year}}
else:
_filter = None
return vectorstore.similarity_search(search.query, filter=_filter)retrieval_chain = query_analyzer | retrieval我们现在可以在之前出现问题的输入上运行这个链式流程,并看到它只返回了那一年的结果!
results = retrieval_chain.invoke("2023年发表的RAG教程")[(doc.metadata["title"], doc.metadata["publish_date"]) for doc in results]输出结果为:
[('入门多模LLM', '2023-12-20 00:00:00'),
('LangServe和LangChain模板网络研讨会', '2023-11-02 00:00:00'),
('入门多模LLM', '2023-12-20 00:00:00'),
('从零开始构建研究助手', '2023-11-16 00:00:00')]快速入门
LangChain拥有多个组件,旨在帮助构建问答应用程序和RAG应用程序。为了熟悉这些组件,我们将构建一个简单的问答应用程序,使用文本数据源。在此过程中,我们将介绍典型的问答架构,讨论相关的LangChain组件,并提供更高级的问答技术的其他资源。我们还将了解LangSmith如何帮助我们跟踪和理解我们的应用程序。随着应用程序的复杂性增加,LangSmith将变得越来越有用。
架构
我们将创建一个典型的RAG应用程序,如问答介绍中所述,它由两个主要组件组成:
索引:用于从源中摄取数据并进行索引的流水线。这通常是离线完成的。
检索和生成:实际的RAG链,它会在运行时接收用户查询并从索引中检索相关数据,然后将其传递给模型。
从原始数据到答案的完整过程如下所示:
索引
- 加载:首先我们需要加载数据。我们将使用DocumentLoaders来完成这一步。
- 拆分:Text splitters将大型的
Documents拆分成较小的块。这对于索引数据和将数据传递到模型中都很有用,因为较大的块更难搜索,并且无法适应模型的有限上下文窗口。 - 存储:我们需要一个地方来存储和索引我们的拆分,以便以后进行搜索。通常使用VectorStore和Embeddings模型来完成此操作。
检索和生成
设置
依赖关系
在本教程中,我们将使用OpenAI聊天模型、嵌入和Chroma向量存储,但这里展示的所有内容都适用于任何ChatModel或LLM、Embeddings和VectorStore或Retriever。
我们将使用以下软件包:
%pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai chromadb bs4我们需要为嵌入模型设置环境变量OPENAI_API_KEY,可以直接设置,也可以从.env文件中加载,示例如下:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# import dotenv
# dotenv.load_dotenv()LangSmith
使用LangChain构建的许多应用程序都包含多个步骤,需要多次调用LLM。随着这些应用程序变得越来越复杂,能够检查链路或代理中确切发生了什么变得至关重要。最好的方法是使用LangSmith (opens in a new tab)。
请注意,LangSmith不是必需的,但它是有用的。如果您确实想使用LangSmith,请在上面的链接上注册后,确保设置环境变量以开始记录跟踪:
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()预览
在本指南中,我们将在Lilian Weng的LLM Powered Autonomous Agents (opens in a new tab)博文上构建一个问答应用程序,以便于我们提问关于博文内容的问题。
我们可以创建一个简单的索引流水线和RAG链,只需约20行代码即可完成:
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitterimport ChatModelTabs from "@theme/ChatModelTabs";
# 加载、拆分和索引博文内容。
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# 使用相关的博文片段来检索和生成。
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)rag_chain.invoke("什么是任务分解?")'任务分解是一种将复杂任务分解为较小和更简单步骤的技术。它可以通过像Chain of Thought或Tree of Thoughts的提示技术,或者使用任务特定的说明或人类输入来完成。任务分解有助于代理提前规划和更有效地管理复杂任务。'# 清理
vectorstore.delete_collection()请查看LangSmith链路 (opens in a new tab)
详细指南
让我们逐步了解上述代码的每一步,以便真正理解发生了什么。
1. 索引:加载 {#indexing-load}
首先,我们需要加载博文内容。为此,我们可以使用DocumentLoaders,这是一种从源加载数据并返回Documents (opens in a new tab)列表的对象。Document是一个具有一些page_content(字符串)和metadata(字典)的对象。
在这种情况下,我们将使用WebBaseLoader,它使用urllib从Web URL加载HTML,并使用BeautifulSoup将其解析为文本。我们可以通过通过bs_kwargs传递参数给BeautifulSoup解析器来自定义HTML到文本的解析(参见BeautifulSoup文档 (opens in a new tab))。在这种情况下,只有具有"class"为"post-content"、"post-title"或"post-header"的HTML标签是相关的,因此我们将删除所有其他标签。
import bs4
from langchain_community.document_loaders import WebBaseLoader
# Only keep post title, headers, and content from the full HTML.
bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content"))
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs={"parse_only": bs4_strainer},
)
docs = loader.load()len(docs[0].page_content)42824print(docs[0].page_content[:500])
LLM Powered Autonomous Agents
Date: June 23, 2023 | Estimated Reading Time: 31 min | Author: Lilian Weng
构建以LLM(大型语言模型)作为核心控制器的代理是一个很酷的概念。几个概念验证演示,如AutoGPT,GPT-Engineer和BabyAGI,都是令人鼓舞的例子。LLM的潜力超越了生成写作副本、故事、文章和程序的能力;它可以被构建成一个功能强大的通用问题求解器。
代理系统概述#
在深入了解
DocumentLoader:从源加载数据并作为Documents列表进行加载的对象。
- 文档:如何使用
DocumentLoader的详细文档。 - 集成:160多个可供选择的集成。
- 接口 (opens in a new tab):基本接口的API参考。
2.索引:分割 {#indexing-split}
我们加载的文档超过42k个字符,这太长了,无法适应许多模型的上下文窗口。即使对于能够适应完整帖子的模型,模型也可能很难在非常长的输入中找到信息。
为了处理这个问题,我们将把Document分成块,以便进行嵌入和向量存储。这样应该能够帮助我们在运行时仅检索与查询最相关的部分的博客文章。
在这种情况下,我们将我们的文档分成1000个字符一块,块之间重叠200个字符。重叠有助于缓解将语句与与其相关的重要上下文分开的可能性。我们使用RecursiveCharacterTextSplitter,该分割器将使用换行等常见的分隔符递归地拆分文档,直到每个块的大小适当为止。这是通用文本用例的推荐文本分割器。
我们设置add_start_index=True,这样每个分割的文档在初始文档中的起始位置的字符索引就被保留为元数据属性“start_index”。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, add_start_index=True
)
all_splits = text_splitter.split_documents(docs)len(all_splits)66len(all_splits[0].page_content)969all_splits[10].metadata{'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/',
'start_index': 7056}深入了解
TextSplitter:将Document列表分割成较小块的对象。是DocumentTransformer的子类。
- 探索"上下文感知分割器",它保留了每个分割在原始
Document中的位置(“上下文”): - Markdown文件 - 代码(py或js)
- 科学论文
- 接口 (opens in a new tab):基本接口的API参考。
DocumentTransformer:对一组Document执行变换的对象。
- 文档:如何使用
DocumentTransformers的详细文档。 - 集成
- 接口 (opens in a new tab):基本接口的API参考。
3.索引:存储 {#indexing-store}
现在我们需要对66个文本块进行索引,以便在运行时可以对它们进行搜索。最常见的方法是嵌入每个文档分割的内容,并将这些嵌入插入到向量数据库(或向量存储)中。当我们想要对我们的分割进行搜索时,我们会获取一个文本搜索查询,对其进行嵌入,然后执行某种“相似度”搜索,以识别与我们查询嵌入最相似的存储分割。最简单的相似度度量是余弦相似度-我们测量每对嵌入之间的角度的余弦值(它们是高维向量)。
我们可以使用Chroma向量存储和OpenAIEmbeddings模型一次性嵌入和存储所有文档分割。
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())深入了解
Embeddings:文本嵌入模型的包装器,用于将文本转换为嵌入。
- 文档:如何使用嵌入的详细文档。
- 集成:30多个可供选择的集成。
- 接口 (opens in a new tab):基本接口的API参考。
VectorStore:向量数据库的包装器,用于存储和查询嵌入。
- 文档:如何使用向量存储的详细文档。
- 集成:40多个可供选择的集成。
- 接口 (opens in a new tab):基本接口的API参考。
这完成了索引部分的流程。在这一点上,我们拥有了一个可查询的向量存储,其中包含了我们的博客文章的分块内容。给定一个用户问题,理想情况下,我们应该能够返回回答该问题的博客文章的片段。
4.检索和生成:检索 {#retrieval-and-generation-retrieve}
现在让我们编写实际的应用逻辑。我们想创建一个简单的应用程序,接受用户提出的问题,搜索与该问题相关的文档,将检索到的文档和初始问题传递给模型,然后返回一个答案。
首先,我们需要定义我们在文档上进行搜索的逻辑。LangChain定义了一个检索器接口,用于包装可以根据字符串查询返回相关Documents的索引。
最常见的检索器类型是VectorStoreRetriever,它使用向量存储的相似度搜索功能来方便检索。任何VectorStore都可以很容易地通过VectorStore.as_retriever()转换为Retriever:
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6})retrieved_docs = retriever.invoke("What are the approaches to Task Decomposition?")len(retrieved_docs)6print(retrieved_docs[0].page_content)Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.7个等号开始,7个等号结束### 更深入了解
向量存储通常用于检索,但还有其他方法可以进行检索。
Retriever: 一个根据文本查询返回Document的对象
- 文档: 关于接口和内置检索技术的进一步文档。其中包括:
MultiQueryRetriever生成输入问题的变种以提高检索命中率。MultiVectorRetriever(下图)生成嵌入的变种,也是为了提高检索命中率。最大边际相关性选择相关性和差异性 (opens in a new tab)中检索到的文档,以避免传递重复的上下文。- 在使用元数据过滤器进行向量存储检索时可以对文档进行过滤,例如使用自查询检索器。
- 集成: 与检索服务的集成。
- 接口 (opens in a new tab): 基础接口的API参考。
5. 检索和生成: 生成 {#retrieval-and-generation-generate}
让我们将所有内容整合到一起,形成一个链条,该链条接收一个问题,检索相关文档,构建一个提示,将其传递给模型,并解析输出结果。
我们将使用gpt-3.5-turbo OpenAI聊天模型,但可以替换为任何LangChain的LLM或ChatModel。
import Tabs from "@theme/Tabs"; import TabItem from "@theme/TabItem";
<ChatModelTabs
customVarName="llm"
anthropicParams="model="claude-3-sonnet-20240229", temperature=0.2, max_tokens=1024"
/>
我们将使用RAG的提示,该提示已经存储在LangChain的提示中心中(此处 (opens in a new tab))。
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")example_messages = prompt.invoke(
{"context": "填充上下文", "question": "填充问题"}
).to_messages()
example_messages[HumanMessage(content="您是一个用于问答任务的助手。使用以下检索到的上下文片段来回答问题。如果您不知道答案,只需说不知道即可。最多使用三个句子,保持答案简洁。\n问题: 填充问题 \n上下文: 填充上下文 \n答案:")]print(example_messages[0].content)您是一个用于问答任务的助手。使用以下检索到的上下文片段来回答问题。如果您不知道答案,只需说不知道即可。最多使用三个句子,保持答案简洁。
问题: 填充问题
上下文: 填充上下文
答案:我们将使用LCEL Runnable协议定义链条,这样我们可以:
- 以透明方式将组件和函数串联在一起
- 在LangSmith中自动跟踪链条
- 在开箱即用的情况下获取流式处理、异步处理和批处理调用
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)for chunk in rag_chain.stream("什么是任务分解?"):
print(chunk, end="", flush=True)任务分解是一种将复杂任务分解为较小和更简单步骤的技术。它涉及将大型任务转化为多个可管理的任务,从而使自主代理或模型更容易理解和执行。任务分解可以通过各种方法来实现,例如使用提示技术,任务特定的指令或人类输入。查看LangSmith跟踪 (opens in a new tab)
更进一步
选择模型
ChatModel: 基于LLM的聊天模型。接受一系列消息并返回一条消息。
- 文档
- 集成: 有超过25个集成供选择。
- 接口 (opens in a new tab): 基础接口的API参考。
LLM: 文本输入文本输出的LLM。接受一个字符串并返回一个字符串。
- 文档
- 集成: 有75多个集成供选择。
- 接口 (opens in a new tab): 基础接口的API参考。
在本地运行模型的RAG指南,请参阅此处。
自定义提示
如上所示,我们可以从提示中心加载提示(例如此处的RAG提示 (opens in a new tab))。同时,提示也可以很容易地进行自定义:
from langchain_core.prompts import PromptTemplate
template = """使用以下上下文片段来回答最后的问题。
如果您不知道答案,只需说不知道,不要试图胡乱回答。
最多使用三个句子,并尽量简明扼要。
在答案的最后始终要说"感谢您的提问!"
{context}
问题:{question}
有帮助的答案:"""
custom_rag_prompt = PromptTemplate.from_template(template)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| custom_rag_prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("什么是任务分解?")'任务分解是一种将复杂任务分解为较小和更简单步骤的技术。通过将大型任务转化为多个可管理的任务,以更系统和组织化的方式解决问题。谢谢您的提问!'查看LangSmith跟踪 (opens in a new tab)
后续步骤
在短时间内我们已经涵盖了很多内容。在上述各节以及更深入了解中提到的Go deeper源代码之外,下一步可以探索的功能、集成和扩展包括:
快速开始
在本指南中,我们将介绍创建基于 SQL 数据库的问答链和代理的基本方法。这些系统将允许我们对 SQL 数据库中的数据提问,并返回自然语言的答案。两者之间的主要区别在于,我们的代理可以循环查询数据库,以回答问题。
⚠️ 安全注意事项 ⚠️
构建 SQL 数据库的问答系统需要执行模型生成的 SQL 查询。这样做存在风险。请确保数据库连接权限始终尽量限制在链/代理所需的范围内。这将减轻但不会消除构建模型驱动系统的风险。有关一般安全最佳实践的更多信息,请参阅此处。
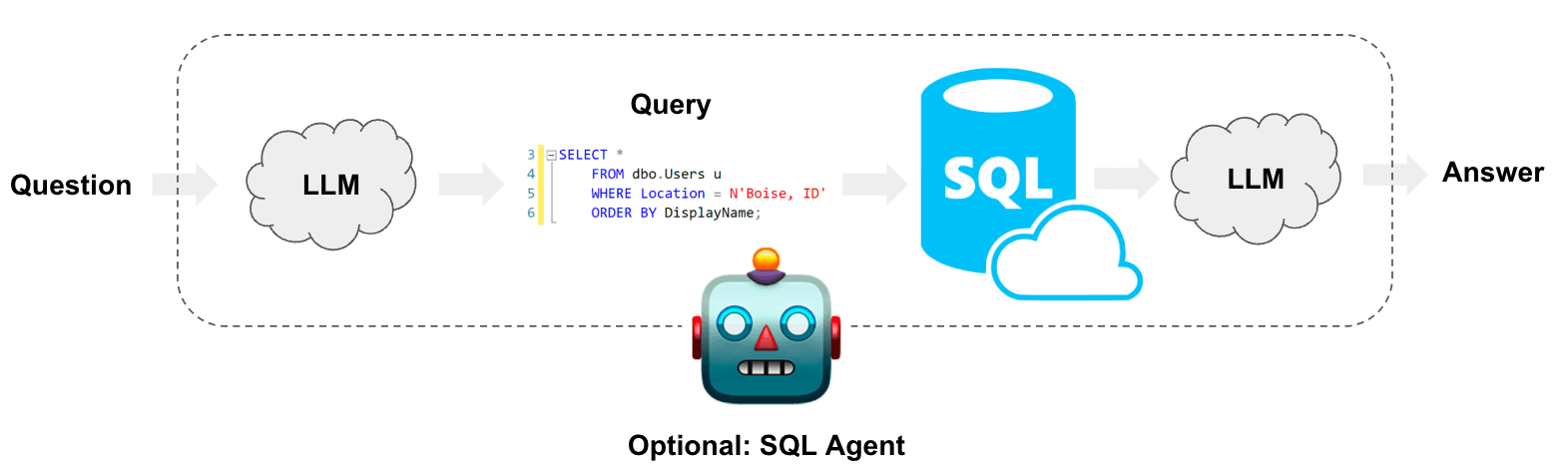
架构
从高层来看,任何 SQL 链和代理的步骤如下:
- 将问题转换为 SQL 查询:模型将用户输入转换为 SQL 查询。
- 执行 SQL 查询:执行 SQL 查询。
- 回答问题:模型使用查询结果回答用户输入的问题。
设置
首先,获取所需的软件包并设置环境变量:
%pip install --upgrade --quiet langchain langchain-community langchain-openai在本指南中,我们将使用 OpenAI 模型:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# 取消下面的注释以使用 LangSmith。非必需。
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"下面的示例将使用 Chinook 数据库的 SQLite 连接。按照这些安装步骤 (opens in a new tab)在与此 notebook 相同的目录中创建 Chinook.db:
- 将此文件 (opens in a new tab)保存为
Chinook_Sqlite.sql - 运行
sqlite3 Chinook.db - 运行
.read Chinook_Sqlite.sql - 测试
SELECT * FROM Artist LIMIT 10;
现在,Chinhook.db 已经在我们的目录中,我们可以使用基于 SQLAlchemy 的 SQLDatabase 类与其交互:
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(db.dialect)
print(db.get_usable_table_names())
db.run("SELECT * FROM Artist LIMIT 10;")运行结果:
sqlite
['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
[(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains'), (6, 'Antônio Carlos Jobim'), (7, 'Apocalyptica'), (8, 'Audioslave'), (9, 'BackBeat'), (10, 'Billy Cobham')]太好了!我们有一个可以查询的 SQL 数据库。现在让我们尝试将其连接到一个 LLM。
链
让我们创建一个简单的链,它接受一个问题,将其转换为 SQL 查询,执行查询,并使用查询结果回答原始问题。
将问题转换为 SQL 查询
SQL 链或代理的第一步是接受用户输入并将其转换为 SQL 查询。LangChain 提供了一个内置链来实现这个功能:create_sql_query_chain (opens in a new tab)。
from langchain.chains import create_sql_query_chain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
chain = create_sql_query_chain(llm, db)
response = chain.invoke({"question": "有多少员工"})
response运行结果:
'SELECT COUNT(*) FROM Employee'我们可以执行这个查询以确保它是有效的:
db.run(response)运行结果:
[(8,)]我们可以查看LangSmith 跟踪 (opens in a new tab)以更好地了解此链的操作。我们还可以直接检查链的提示信息。我们可以查看提示(如下所示),可以看到它是:
- 方言特定的。在本例中明确引用了 SQLite。
- 提供了所有可用表的定义。
- 为每个表提供了三个示例行。
这种技术受到了诸如此类 (opens in a new tab)论文的启发,该论文建议向用户显示示例行,并明确指出表格有助于提高性能。我们还可以查看完整的提示:
chain.get_prompts()[0].pretty_print()执行 SQL 查询
现在我们已经生成了一个 SQL 查询,我们将要执行它。这是创建 SQL 链中最危险的部分。请仔细考虑是否可以安全地在数据上运行自动查询。尽量尽可能减少数据库连接权限。在查询执行之前,考虑添加一个人工审批步骤给您的链(参见下文)。
我们可以使用 QuerySQLDatabaseTool 方便地将查询执行添加到我们的链中:
from langchain_community.tools.sql_database.tool import QuerySQLDataBaseTool
execute_query = QuerySQLDataBaseTool(db=db)
write_query = create_sql_query_chain(llm, db)
chain = write_query | execute_query
chain.invoke({"question": "有多少员工"})运行结果:
'[(8,)]'回答问题
现在我们已经找到了一种自动生成和执行查询的方法,我们只需要将原始问题和 SQL 查询结果组合起来生成最终答案。我们可以通过再次传递问题和结果到 LLM 来实现这一点:
from operator import itemgetter
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough
answer_prompt = PromptTemplate.from_template(
"""给定以下用户问题、相应的 SQL 查询和 SQL 结果,请回答用户问题。
问题:{question}
SQL 查询:{query}
SQL 结果:{result}
答案:"""
)
answer = answer_prompt | llm | StrOutputParser()
chain = (
RunnablePassthrough.assign(query=write_query).assign(
result=itemgetter("query") | execute_query
)
| answer
)
chain.invoke({"question": "有多少员工"})运行结果:
'有 8 名员工。'=======
下一步
对于更复杂的查询生成,我们可以创建few-shot prompts或添加查询检查步骤。了解更多高级技巧,请查看以下内容:
Agents
LangChain具有SQL Agent,它提供了一种与SQL数据库更灵活交互的方式。使用SQL Agent的主要优势是:
- 它可以根据数据库的模式和内容回答问题(例如描述特定表)。
- 它可以通过运行生成的查询、捕获回溯并正确重新生成来从错误中恢复。
- 它可以回答需要多个依赖查询的问题。
- 它将只考虑相关表的模式,从而节省令牌。
要初始化代理,我们使用create_sql_agent函数。此代理包含SQLDatabaseToolkit,其中包含以下工具:
- 创建和执行查询
- 检查查询语法
- 检索表描述
- ...等等
初始化代理
from langchain_community.agent_toolkits import create_sql_agent
agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)agent_executor.invoke(
{
"input": "列出每个国家的总销售额。哪个国家的客户消费最多?"
}
)[1m> 进入新的代理执行链...[0m
[32;1m[1;3m
调用: `sql_db_list_tables` 使用 `{}`
[0m[38;5;200m[1;3mAlbum, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track[0m[32;1m[1;3m
调用: `sql_db_schema` 使用 `Invoice,Customer`
[0m[33;1m[1;3m
CREATE TABLE "Customer" (
"CustomerId" INTEGER NOT NULL,
"FirstName" NVARCHAR(40) NOT NULL,
"LastName" NVARCHAR(20) NOT NULL,
"Company" NVARCHAR(80),
"Address" NVARCHAR(70),
"City" NVARCHAR(40),
"State" NVARCHAR(40),
"Country" NVARCHAR(40),
"PostalCode" NVARCHAR(10),
"Phone" NVARCHAR(24),
"Fax" NVARCHAR(24),
"Email" NVARCHAR(60) NOT NULL,
"SupportRepId" INTEGER,
PRIMARY KEY ("CustomerId"),
FOREIGN KEY("SupportRepId") REFERENCES "Employee" ("EmployeeId")
)
/*
Customer表的3行:
CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId
1 Luís Gonçalves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 São José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 3
2 Leonie Köhler None Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 5
3 François Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3
*/
CREATE TABLE "Invoice" (
"InvoiceId" INTEGER NOT NULL,
"CustomerId" INTEGER NOT NULL,
"InvoiceDate" DATETIME NOT NULL,
"BillingAddress" NVARCHAR(70),
"BillingCity" NVARCHAR(40),
"BillingState" NVARCHAR(40),
"BillingCountry" NVARCHAR(40),
"BillingPostalCode" NVARCHAR(10),
"Total" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("InvoiceId"),
FOREIGN KEY("CustomerId") REFERENCES "Customer" ("CustomerId")
)
/*
Invoice表的3行:
InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total
1 2 2009-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 1.98
2 4 2009-01-02 00:00:00 Ullevålsveien 14 Oslo None Norway 0171 3.96
3 8 2009-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94
*/[0m[32;1m[1;3m
调用: `sql_db_query` 使用 `SELECT c.Country, SUM(i.Total) AS TotalSales FROM Invoice i JOIN Customer c ON i.CustomerId = c.CustomerId GROUP BY c.Country ORDER BY TotalSales DESC LIMIT 10;`
响应: 要列出每个国家的总销售额,我可以查询“Invoice”和“Customer”表。我将根据“CustomerId”列联接这些表,并按照“BillingCountry”列对结果进行分组。然后,我将计算“Total”列的总和以获取每个国家的总销售额。最后,我将按照总销售额的降序对结果进行排序。
这是SQL查询语句:
```sql
SELECT c.Country, SUM(i.Total) AS TotalSales
FROM Invoice i
JOIN Customer c ON i.CustomerId = c.CustomerId
GROUP BY c.Country
ORDER BY TotalSales DESC
LIMIT 10;
```
现在,我将执行此查询以获取每个国家的总销售额。
[0m[36;1m[1;3m[('USA', 523.0600000000003), ('Canada', 303.9599999999999), ('France', 195.09999999999994), ('Brazil', 190.09999999999997), ('Germany', 156.48), ('United Kingdom', 112.85999999999999), ('Czech Republic', 90.24000000000001), ('Portugal', 77.23999999999998), ('India', 75.25999999999999), ('Chile', 46.62)][0m[32;1m[1;3m每个国家的总销售额如下:
1. 美国:523.06美元
2. 加拿大:303.96美元
3. 法国:195.10美元
4. 巴西:190.10美元
5. 德国:156.48美元
6. 英国:112.86美元
7. 捷克共和国:90.24美元
8. 葡萄牙:77.24美元
9. 印度:75.26美元
10. 智利:46.62美元
回答第二个问题,消费最多的国家是美国,总销售额为523.06美元。[0m
[1m> 完成链条。[0m
{'input': '列出每个国家的总销售额。哪个国家的客户消费最多?',
'output': '每个国家的总销售额如下:\n\n1. 美国:523.06美元\n2. 加拿大:303.96美元\n3. 法国:195.10美元\n4. 巴西:190.10美元\n5. 德国:156.48美元\n6. 英国:112.86美元\n7. 捷克共和国:90.24美元\n8. 葡萄牙:77.24美元\n9. 印度:75.26美元\n10. 智利:46.62美元\n\n回答第二个问题,消费最多的国家是美国,总销售额为523.06美元。'}agent_executor.invoke({"input": "描述playlisttrack表"})[1m> 进入新的代理执行链...[0m
[32;1m[1;3m
调用: `sql_db_list_tables` 使用 `{}`
[0m[38;5;200m[1;3mAlbum, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track[0m[32;1m[1;3m
调用: `sql_db_schema` 使用 `PlaylistTrack`
[0m[33;1m[1;3m
CREATE TABLE "PlaylistTrack" (
"PlaylistId" INTEGER NOT NULL,
"TrackId" INTEGER NOT NULL,
PRIMARY KEY ("PlaylistId", "TrackId"),
FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"),
FOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId")
)
/*
PlaylistTrack表的3行:
PlaylistId TrackId
1 3402
1 3389
1 3390
*/[0m[32;1m[1;3m`PlaylistTrack`表有两列:`PlaylistId`和`TrackId`。它是一个联接表,表示播放列表和音轨之间的多对多关系。
这是`PlaylistTrack`表的模式:
```
CREATE TABLE "PlaylistTrack" (
"PlaylistId" INTEGER NOT NULL,
"TrackId" INTEGER NOT NULL,
PRIMARY KEY ("PlaylistId", "TrackId"),
FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"),
FOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId")
)
```
`PlaylistId`列是对`Playlist`表中的`PlaylistId`列的外键引用。`TrackId`列是对`Track`表中的`TrackId`列的外键引用。
这是`PlaylistTrack`表的三个示例行:
```
PlaylistId TrackId
1 3402
1 3389
1 3390
```
如果需要其他帮助,请随时告诉我。[0m
[1m> 完成链条。[0m
{'input': '描述playlisttrack表',
'output': '`PlaylistTrack`表有两列:`PlaylistId`和`TrackId`。它是一个联接表,表示播放列表和音轨之间的多对多关系。\n\n这是`PlaylistTrack`表的模式:\n\n```\nCREATE TABLE "PlaylistTrack" (\n\t"PlaylistId" INTEGER NOT NULL, \n\t"TrackId" INTEGER NOT NULL, \n\tPRIMARY KEY ("PlaylistId", "TrackId"), \n\tFOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"), \n\tFOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId")\n)\n```\n\n`PlaylistId`列是对`Playlist`表中的`PlaylistId`列的外键引用。`TrackId`列是对`Track`表中的`TrackId`列的外键引用。\n\n这是`PlaylistTrack`表的三个示例行:\n\n```\nPlaylistId TrackId\n1 3402\n1 3389\n1 3390\n```\n\n如果需要其他帮助,请随时告诉我。'}### 下一步有关如何使用和自定义代理的更多信息,请参阅代理页面。# 快速入门
在本指南中,我们将介绍创建调用工具的链和代理的基本方法。工具可以是几乎任何东西 - API、函数、数据库等。工具使我们能够扩展模型的能力,使其不仅能够输出文本/消息。使用工具与模型的关键是正确提示模型并解析其响应,以便选择合适的工具并为其提供合适的输入。
设置
我们需要安装以下软件包来完成本指南:
%pip install --upgrade --quiet langchain langchain-openai并设置以下环境变量:
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# 如果您想使用LangSmith,请取消下面的注释
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()创建工具
首先,我们需要创建一个要调用的工具。对于本示例,我们将从一个函数创建一个自定义工具。有关创建自定义工具的更多信息,请参阅此指南。
from langchain_core.tools import tool
@tool
def multiply(first_int: int, second_int: int) -> int:
"""Multiply two integers together."""
return first_int * second_intprint(multiply.name)
print(multiply.description)
print(multiply.args)multiply
multiply(first_int: int, second_int: int) -> int - Multiply two integers together.
{'first_int': {'title': 'First Int', 'type': 'integer'}, 'second_int': {'title': 'Second Int', 'type': 'integer'}}multiply.invoke({"first_int": 4, "second_int": 5})20链
如果我们知道只需要使用工具固定次数,我们可以创建一个链来实现。让我们创建一个简单的链,只需将用户指定的数字相乘。

函数调用
使用工具与LLM一起使用最可靠的方法之一是使用函数调用API(有时也称为工具调用或并行函数调用)。这仅适用于显式支持函数调用(如OpenAI模型)的模型。要了解更多信息,请查看函数调用指南。
首先,我们将定义我们的模型和工具。我们将从一个单一工具 multiply 开始。
from langchain_openai.chat_models import ChatOpenAI
model = ChatOpenAI(model="gpt-3.5-turbo-1106")然后,我们将将我们的LangChain Tool转换为OpenAI格式的JSONSchema函数,并绑定为tools参数,以供所有ChatOpenAI调用使用。由于我们只有一个工具,并且在这个初始链中我们希望确保它始终被使用,我们还将指定 tool_choice。有关这些参数的更多信息,请参阅OpenAI聊天API参考 (opens in a new tab):
model_with_tools = model.bind_tools([multiply], tool_choice="multiply")model_with_tools.kwargs["tools"][{'type': 'function',
'function': {'name': 'multiply',
'description': 'multiply(first_int: int, second_int: int) -> int - Multiply two integers together.',
'parameters': {'type': 'object',
'properties': {'first_int': {'type': 'integer'},
'second_int': {'type': 'integer'}},
'required': ['first_int', 'second_int']}}}]model_with_tools.kwargs["tool_choice"]{'type': 'function', 'function': {'name': 'multiply'}}现在,我们将用JsonOutputToolsParser将我们的工具调用模型与一个构成链。JsonOutputToolsParser是一个内置的LangChain输出解析器,它将OpenAI函数调用的响应转换为包含工具和用于调用它们的参数的{"type": "TOOL_NAME", "args": {...}}字典的列表。
from langchain.output_parsers import JsonOutputToolsParser
chain = model_with_tools | JsonOutputToolsParser()
chain.invoke("What's four times 23")[{'type': 'multiply', 'args': {'first_int': 4, 'second_int': 23}}]由于我们知道我们总是调用 multiply 工具,我们可以稍微简化我们的输出,只返回 multiply 工具的参数,使用 JsonOutputKeyToolsParser。为了进一步简化,我们还将指定 first_tool_only=True,这样输出解析器返回的只是第一个工具调用,而不是工具调用的列表。
from langchain.output_parsers import JsonOutputKeyToolsParser
chain = model_with_tools | JsonOutputKeyToolsParser(
key_name="multiply", first_tool_only=True
)
chain.invoke("What's four times 23"){'first_int': 4, 'second_int': 23}调用工具
太棒了!我们能够生成工具调用。但是,如果我们想要实际调用工具怎么办?我们只需要将它们传递给工具即可:
from operator import itemgetter
# 注意:`multiply` 结尾的 `.map()` 可以允许我们传入一个 `multiply` 参数列表,而不是一个单独的参数。
chain = (
model_with_tools
| JsonOutputKeyToolsParser(key_name="multiply", first_tool_only=True)
| multiply
)
chain.invoke("What's four times 23")92代理
当我们知道任何用户输入所需的特定工具使用顺序时,链非常有用。但对于某些用例,我们使用工具的次数取决于输入。在这些情况下,我们希望让模型自己决定使用工具的次数和顺序。代理可以实现这一点。
LangChain提供了许多内置代理,针对不同的用例进行了优化。在这里阅读所有代理类型的相关信息。
作为示例,让我们试试OpenAI工具代理,它利用了新的OpenAI工具调用API(这仅适用于最新的OpenAI模型,与函数调用不同,模型可以一次返回多个函数调用)。

from langchain import hub
from langchain.agents import AgentExecutor, create_openai_tools_agent
from langchain_openai import ChatOpenAIprompt = hub.pull("hwchase17/openai-tools-agent")
prompt.messages[SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=[], template='You are a helpful assistant')),
MessagesPlaceholder(variable_name='chat_history', optional=True),
HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['input'], template='{input}')),
MessagesPlaceholder(variable_name='agent_scratchpad')]代理工具还很棒,因为它们使使用多个工具变得容易。要了解如何构建使用多个工具的链式结构,请查看Chains with multiple tools页面。
@tool
def add(first_int: int, second_int: int) -> int:
"Add two integers."
return first_int + second_int
@tool
def exponentiate(base: int, exponent: int) -> int:
"Exponentiate the base to the exponent power."
return base**exponent
tools = [multiply, add, exponentiate]# 选择将驱动代理的LLM
# 只有某些模型支持这个
model = ChatOpenAI(model="gpt-3.5-turbo-1106", temperature=0)
# 构建OpenAI Tools代理
agent = create_openai_tools_agent(model, tools, prompt)# 通过传入代理和工具创建代理执行器
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)有了代理,我们可以询问需要任意多次使用工具的问题:
agent_executor.invoke(
{
"input": "Take 3 to the fifth power and multiply that by the sum of twelve and three, then square the whole result"
}
)[1m> 进入新的AgentExecutor链...[0m
[32;1m[1;3m
调用: `exponentiate` 使用 `{'base': 3, 'exponent': 5}`
[0m[38;5;200m[1;3m243[0m[32;1m[1;3m
调用: `add` 使用 `{'first_int': 12, 'second_int': 3}`
[0m[33;1m[1;3m15[0m[32;1m[1;3m
调用: `multiply` 使用 `{'first_int': 243, 'second_int': 15}`
[0m[36;1m[1;3m3645[0m[32;1m[1;3m
调用: `exponentiate` 使用 `{'base': 3645, 'exponent': 2}`
[0m[38;5;200m[1;3m13286025[0m[32;1m[1;3m将3的五次方与12和3的和相乘,然后将整个结果平方的结果为13,286,025。[0m
[1m> 完成链式结构。[0m
{'input': 'Take 3 to the fifth power and multiply that by the sum of twelve and three, then square the whole result',
'output': '将3的五次方与12和3的和相乘,然后将整个结果平方的结果为13,286,025。'}下一步操作
在这里,我们已经介绍了使用链式结构和代理的基本方法。我们建议您在下面的章节中继续探索:
- 代理工具:与代理相关的一切。
- 在多个工具之间进行选择:如何创建从多个工具中选择的工具链。
- 提示工具使用:如何创建直接提示模型而不使用函数调用API的工具链。
- 并行工具使用:如何一次调用多个工具的工具链。